
構造化データと構造化マークアップの基本を理解する
検索エンジンがWebページの内容を正確に理解するためには、単なるテキスト情報だけでは不十分な場面が数多く存在します。人間であれば文脈から「これは商品の価格だ」「これはイベントの開催日時だ」と直感的に理解できる情報も、検索エンジンのクローラーにとっては判別が難しいことがあります。この課題を解決するために生まれたのが、構造化データと構造化マークアップという技術です。
構造化データとは、Webページ上の情報に意味的なラベルを付与し、機械が読み取りやすい形式で記述されたデータのことを指します。例えば、あるページに「東京タワー」という文字列があった場合、それが観光スポットなのか、企業名なのか、あるいは単なる比喩表現なのか、機械には判断がつきません。構造化データを使えば「これは観光名所である」「所在地は東京都港区である」「営業時間は9時から23時である」といった具体的な属性情報を明示的に伝えることができます。
構造化マークアップとは、この構造化データをHTMLに埋め込む作業そのもの、またはその記述方法を指す用語です。両者は実質的に同じ概念を指すことが多く、Web制作の現場では互換的に使用されています。Googleをはじめとする検索エンジンは、このマークアップ情報を活用してリッチリザルトと呼ばれる拡張された検索結果を表示します。これにより、ユーザーは検索結果ページ上でより詳細な情報を得ることができ、クリック前に内容を把握しやすくなります。
SEOの観点から見ると、構造化マークアップは直接的なランキング要因ではないとGoogleは公式に述べています。しかし、リッチリザルトによってクリック率が向上すれば、間接的にサイトへのトラフィック増加につながります。また、検索エンジンがページ内容を正確に理解することで、適切な検索クエリに対してページが表示される可能性も高まります。特に近年では、AIによる検索体験の進化に伴い、構造化データの重要性はますます増しています。
構造化データが検索エンジンに与える影響
検索エンジンのクローラーはWebページを巡回し、そのコンテンツをインデックスに登録します。この過程で、クローラーはHTMLのマークアップ情報を解析し、ページの内容や構造を把握しようとします。構造化データが適切に実装されているページでは、クローラーがより正確かつ効率的に情報を理解できます。
Googleの場合、構造化データはナレッジグラフと呼ばれる巨大な知識データベースの構築にも活用されています。ナレッジグラフとは、人物、場所、組織、イベントなど、現実世界のエンティティ(実体)とその関係性を網羅的に整理したデータベースです。Webページに記述された構造化データは、このナレッジグラフの精度向上に貢献し、結果として検索結果の品質改善につながっています。
検索エンジンが構造化データを活用する具体的な場面としては、まずリッチリザルトの表示があります。レシピサイトであれば調理時間やカロリー、レビュー評価が検索結果に直接表示されます。ECサイトでは価格や在庫状況、商品レビューが表示されることで、ユーザーは検索結果を見ただけで購入判断に必要な情報を得られます。イベント情報では開催日時や場所が明示され、ユーザーの利便性が大幅に向上します。
schema.orgという共通ボキャブラリの誕生
構造化データの記述には共通の語彙(ボキャブラリ)が必要です。各検索エンジンや各Webサイトが独自の形式でデータを記述していたのでは、相互運用性が失われてしまいます。この問題を解決するために、2011年にGoogle、Microsoft(Bing)、Yahoo!が共同でschema.orgを立ち上げました。後にロシアの検索エンジンYandexも参加し、現在では主要な検索エンジンすべてがschema.orgの語彙を認識しています。
schema.orgでは、数百種類のタイプ(型)と数千のプロパティ(属性)が定義されています。例えばPersonタイプには、name(名前)、jobTitle(職業)、worksFor(勤務先)といったプロパティがあり、それぞれの値として文字列や別のタイプを指定できます。このように階層的かつ体系的に整理された語彙を使うことで、あらゆる種類の情報を構造化することが可能になっています。
schema.orgは継続的に更新されており、新しいタイプやプロパティが追加されています。例えば、新型コロナウイルス感染症の流行を受けて、健康関連のスキーマが拡充されました。また、求人情報やオンラインコースといった新しい領域のスキーマも順次追加されています。Web制作者は、schema.orgの公式サイトで最新のドキュメントを確認し、適切なマークアップを実装することが推奨されます。
schema.orgは、Google、Microsoft、Yahoo、Yandexが共同で運営する構造化データのボキャブラリ提供プロジェクトです。公式サイトでは、すべてのタイプとプロパティの定義、使用例、最新の更新情報を確認できます。
構造化データの記述形式を徹底比較する
構造化データをHTMLに埋め込むための記述形式として、現在主に使用されているものは3種類あります。JSON-LD、Microdata、RDFaの3形式で、それぞれに特徴と適した使用場面があります。Googleは公式にJSON-LDを推奨しており、実際の導入率でもJSON-LDが圧倒的なシェアを占めています。しかし、既存システムとの互換性や特定の要件によっては、他の形式が適している場合もあります。
JSON-LDが推奨される理由とその構造
JSON-LD(JavaScript Object Notation for Linked Data)は、JSON形式を拡張してLinked Dataを記述できるようにしたフォーマットです。scriptタグ内にJSONオブジェクトとして構造化データを記述するため、HTMLの本文とは完全に分離されます。この特性により、既存のHTMLを一切変更することなく構造化データを追加できるという大きなメリットがあります。
JSON-LDの基本構造は、@contextと@typeという2つの特別なキーから始まります。@contextは使用するボキャブラリを指定するもので、通常はschema.orgのURLを記述します。@typeは記述するエンティティの種類を指定し、schema.orgで定義されたタイプ名を使用します。その後に続くキーと値のペアが、そのエンティティの具体的な属性情報となります。
JSON-LDがGoogleに推奨される理由は複数あります。
- HTMLの構造に依存しないため、ページのリデザインやCMSの変更があっても構造化データへの影響が最小限で済みます
- 動的なコンテンツに対応しやすく、JavaScriptで生成されたJSON-LDもGoogleは認識できるため、SPAやヘッドレスCMSとの相性が良好です
- 記述の検証やデバッグが容易であり、JSONバリデータやGoogleのリッチリザルトテストツールで即座にエラーを検出できます
Microdataの特徴と使用場面
Microdataは、HTMLの属性としてタグに直接構造化データを埋め込む形式です。itemscope、itemtype、itempropという3つの属性を使用し、既存のHTMLタグにセマンティックな意味を付与します。itemscopeは新しいアイテムの開始を示し、itemtypeはそのアイテムの種類をURLで指定します。itempropはアイテムの属性名を示し、タグの内容や特定の属性値がその属性の値となります。
Microdataの利点は、HTMLの構造と構造化データが完全に同期することです。表示されるコンテンツと構造化データの内容が必ず一致するため、データの整合性が保たれやすくなります。また、HTMLの知識があれば比較的理解しやすく、追加のスクリプトや外部ファイルを必要としません。
一方でMicrodataにはいくつかのデメリットも存在します。HTMLの構造に強く依存するため、デザイン変更時に構造化データも修正が必要になることがあります。また、複雑なデータ構造を表現する場合、HTMLが冗長になりやすいという問題もあります。さらに、動的に生成されるコンテンツには適用が難しく、サーバーサイドでHTMLを生成する段階でマークアップを含める必要があります。
RDFaの高度な表現力と複雑性
RDFa(Resource Description Framework in Attributes)は、もともとRDF(Resource Description Framework)のデータモデルをHTML内で表現するために開発された形式です。vocab、typeof、propertyなどの属性を使用し、Microdataと似た方法でHTMLに構造化データを埋め込みます。しかし、RDFaはより高度な機能を持ち、複数のボキャブラリを組み合わせたり、リソース間の関係を詳細に記述したりすることができます。
RDFaの最大の特徴は、その表現力の高さにあります。prefix属性を使って複数の名前空間を定義し、異なるボキャブラリからのプロパティを混在させることが可能です。また、resource属性を使って明示的にURIを割り当てることで、Linked Dataの原則に完全に準拠した記述ができます。学術データや政府オープンデータなど、データの相互運用性が重視される分野ではRDFaが好まれる傾向にあります。
ただし、RDFaの複雑性は一般的なWebサイトにとってはオーバースペックとなることが多いです。学習コストが高く、エラーが発生しやすいため、SEO目的の構造化マークアップにはあまり推奨されません。また、Googleの構造化データガイドラインでも、RDFaに関するドキュメントはJSON-LDやMicrodataに比べて少なく、サポートが手薄になっている印象があります。
WebDataCommonsの2024年10月の調査によると、構造化データを実装しているWebサイトのうち、JSON-LDを使用しているのは約70%、Microdataが約46%、RDFaはわずか3%となっています。この数値からも、JSON-LDが業界標準として定着していることが明らかです。
以下に3つの記述形式の特徴を比較します。
| 形式 | 記述場所 | HTMLへの影響 | 学習コスト | Google推奨度 | 動的コンテンツ対応 |
|---|---|---|---|---|---|
| JSON-LD | scriptタグ内 | なし | 低い | 最高 | 優れている |
| Microdata | HTML属性 | あり | 中程度 | 中程度 | 困難 |
| RDFa | HTML属性 | あり | 高い | 低い | 困難 |

主要なschema.orgタイプとその実装方法
schema.orgには数百種類のタイプが定義されていますが、実際にGoogleがリッチリザルトとしてサポートしているのはその一部です。ここでは、特に利用頻度が高く、SEO効果も期待できる主要なタイプについて、その用途と実装例を詳しく解説します。各タイプのJSON-LDコードサンプルも含め、実務で即座に活用できる情報を提供します。
HTTP Archive Web Almanac 2024の調査によると、JSON-LDで実装されている主要なschema.orgタイプの採用率は、WebSiteが12.73%、Organizationが7.16%、BreadcrumbListが5.66%、LocalBusinessが3.97%、ItemListが2.44%となっています。
記事コンテンツを表すArticleとNewsArticleとBlogPosting
Webサイトで最も一般的なコンテンツタイプである記事には、Articleタイプとその派生タイプを使用します。Articleは汎用的な記事全般を表し、NewsArticleはニュース記事、BlogPostingはブログ記事を表現するために使用します。これらのタイプを適切にマークアップすることで、Google検索のトップニュースやDiscoverフィードでの表示機会が向上する可能性があります。
Articleタイプの必須プロパティには、headlineがあります。これは記事のタイトルを表し、110文字以内が推奨されています。また、imageプロパティで記事のサムネイル画像を指定し、datePublishedで公開日時、dateModifiedで最終更新日時を記述します。authorプロパティでは記事の執筆者を指定でき、PersonまたはOrganizationタイプを値として使用します。
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "構造化マークアップの完全ガイド",
"image": "https://example.com/images/structured-data-guide.jpg",
"datePublished": "2025-01-15T09:00:00+09:00",
"dateModified": "2025-01-20T14:30:00+09:00",
"author": {
"@type": "Person",
"name": "柏崎剛",
"url": "https://www.tsuyoshikashiwazaki.jp/profile/"
},
"publisher": {
"@type": "Organization",
"name": "SEO対策研究室",
"logo": {
"@type": "ImageObject",
"url": "https://example.com/logo.png"
}
}
}NewsArticleは、速報性のあるニュース記事に適しています。Articleのすべてのプロパティに加えて、dateline(発信地)などのニュース特有のプロパティを使用できます。BlogPostingは個人的な見解や体験を含むブログ記事に適しており、Articleと同様のプロパティを持ちますが、より個人的なコンテンツであることを示します。
FAQPageで検索結果にQ&Aを表示する
FAQPageタイプは、ページがよくある質問とその回答で構成されていることを示します。このマークアップを実装すると、検索結果にアコーディオン形式でQ&Aが表示される可能性があります。これにより、検索結果ページ上でユーザーの疑問に直接回答できるため、クリック前の情報提供として非常に効果的です。
FAQPageの構造は、mainEntityプロパティの配列として複数のQuestionオブジェクトを持ちます。各Questionオブジェクトにはnameプロパティで質問文を、acceptedAnswerプロパティでAnswerオブジェクトを指定します。Answerオブジェクトのtextプロパティに回答文を記述します。回答文にはHTMLを含めることができ、リンクや簡単な書式設定が可能です。
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "構造化データとは何ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "構造化データとは、Webページの情報を検索エンジンが理解しやすい形式で記述したデータです。schema.orgのボキャブラリを使用し、JSON-LDなどの形式でHTMLに埋め込みます。"
}
},
{
"@type": "Question",
"name": "構造化データを実装するメリットは何ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "リッチリザルトによる検索結果の視認性向上、クリック率の改善、検索エンジンによるコンテンツ理解の精度向上などのメリットがあります。"
}
}
]
}FAQPageのマークアップにはいくつかの注意点があります。広告目的のコンテンツや、質問と回答が明確に対応していないコンテンツには使用すべきではありません。また、同一ページに複数のFAQPageを実装することは推奨されず、1ページに1つのFAQPageとして記述することが望ましいです。
WordPressでFAQPage構造化データを実装する際、JSON-LDの手書きは煩雑でエラーを招きやすい問題があります。以下のプラグインは、アコーディオン型とシンプル型の2つの表示タイプを提供しながら、mainEntityやQuestionオブジェクトを自動生成し、リアルタイムプレビューでマークアップの妥当性を確認できます。
HowToで手順をステップバイステップで示す
HowToタイプは、何かを達成するための手順を記述するために使用します。料理レシピ、DIYガイド、ソフトウェアのインストール手順など、段階的な説明が必要なコンテンツに最適です。検索結果では、各ステップがリスト形式で表示されることがあり、ユーザーは検索結果を見るだけで大まかな手順を把握できます。
HowToの構造は、stepプロパティの配列として複数のHowToStepオブジェクトを持ちます。各ステップにはname(ステップ名)、text(詳細説明)、image(手順を示す画像)、url(そのステップへの直接リンク)などを指定できます。また、estimatedCostで推定費用、totalTimeで所要時間、supplyで必要な材料、toolで必要な道具を記述することも可能です。
{
"@context": "https://schema.org",
"@type": "HowTo",
"name": "JSON-LDで構造化データを実装する方法",
"description": "WebページにJSON-LD形式の構造化データを追加する手順を解説します。",
"totalTime": "PT30M",
"step": [
{
"@type": "HowToStep",
"name": "schema.orgでタイプを選択",
"text": "マークアップしたいコンテンツに適したschema.orgのタイプを選択します。記事ならArticle、商品ならProductなど、コンテンツの種類に応じたタイプを使用します。",
"url": "https://example.com/howto#step1"
},
{
"@type": "HowToStep",
"name": "JSON-LDコードを作成",
"text": "選択したタイプに基づいて、@context、@type、必要なプロパティを含むJSONオブジェクトを作成します。",
"url": "https://example.com/howto#step2"
},
{
"@type": "HowToStep",
"name": "HTMLに埋め込む",
"text": "作成したJSONコードをscriptタグで囲み、type="application/ld+json"を指定してHTMLのhead要素またはbody要素に追加します。",
"url": "https://example.com/howto#step3"
}
]
}Productで商品情報を詳細に記述する
ECサイトにとって最も重要な構造化データタイプがProductです。商品名、説明、画像、価格、在庫状況、レビューなど、購買判断に必要なあらゆる情報を構造化できます。検索結果では価格や評価が直接表示され、ユーザーは複数の商品を比較しやすくなります。Googleショッピングへの表示にも構造化データが活用されています。
Productタイプの主要プロパティには、name(商品名)、description(説明)、image(画像URL)、sku(商品コード)、brand(ブランド)があります。価格情報はoffersプロパティ内にOfferオブジェクトとして記述し、price(価格)、priceCurrency(通貨)、availability(在庫状況)、url(商品ページURL)などを指定します。レビュー情報はaggregateRatingプロパティでAggregateRatingオブジェクトとして記述し、平均評価とレビュー数を示します。
{
"@context": "https://schema.org",
"@type": "Product",
"name": "SEO対策完全マニュアル",
"image": "https://example.com/images/seo-manual.jpg",
"description": "初心者から上級者まで対応した、SEO対策の決定版ガイドブック。",
"sku": "SEO-MANUAL-001",
"brand": {
"@type": "Brand",
"name": "SEO対策研究室"
},
"offers": {
"@type": "Offer",
"url": "https://example.com/products/seo-manual",
"priceCurrency": "JPY",
"price": "3980",
"availability": "https://schema.org/InStock",
"seller": {
"@type": "Organization",
"name": "SEO対策研究室"
}
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8",
"reviewCount": "156"
}
}ReviewとAggregateRatingでレビュー情報を表現する
レビューと評価の構造化データは、単独で使用することも、ProductやLocalBusinessなど他のタイプと組み合わせて使用することもできます。Reviewタイプは個別のレビューを表し、AggregateRatingタイプは複数のレビューを集計した評価を表します。検索結果に星評価が表示されることで、視認性と信頼性の両方が向上します。
Reviewタイプには、reviewBody(レビュー本文)、author(レビュアー)、datePublished(投稿日)、reviewRating(このレビューでの評価)などのプロパティがあります。reviewRatingにはRatingオブジェクトを使用し、ratingValue(評価値)、bestRating(最高評価)、worstRating(最低評価)を指定します。
{
"@context": "https://schema.org",
"@type": "Review",
"itemReviewed": {
"@type": "Product",
"name": "SEO対策ツール"
},
"reviewRating": {
"@type": "Rating",
"ratingValue": "5",
"bestRating": "5",
"worstRating": "1"
},
"author": {
"@type": "Person",
"name": "田中太郎"
},
"reviewBody": "非常に使いやすく、SEO対策の効率が大幅に向上しました。",
"datePublished": "2025-01-10"
}AggregateRatingは複数のレビューの集計結果を示すため、ratingValue(平均評価)、reviewCount(レビュー数)、ratingCount(評価数)などを記述します。reviewCountとratingCountの違いは、前者はレビュー本文を伴う評価の数、後者は星評価のみの数を指します。
LocalBusinessで地域ビジネス情報を最適化する
実店舗を持つビジネスにとって、LocalBusinessタイプは非常に重要です。店舗名、住所、電話番号、営業時間、サービス内容などを構造化することで、ローカル検索での表示機会が向上します。Googleマップやローカルパックでの表示にも、構造化データが活用されています。
LocalBusinessは、Restaurant(レストラン)、Hotel(ホテル)、MedicalClinic(医療機関)など、より具体的なサブタイプを持っています。可能な限り具体的なサブタイプを使用することで、より適切なリッチリザルト表示が期待できます。例えば、美容院であればBeautySalon、歯科医院であればDentistタイプを使用します。
{
"@context": "https://schema.org",
"@type": "ProfessionalService",
"name": "株式会社コンテンシャル",
"image": "https://www.contencial.co.jp/wp/wp-content/uploads/2023/08/contencial-logo-big.png",
"address": {
"@type": "PostalAddress",
"streetAddress": "代々木2丁目26-2 第二桑野ビル5D",
"addressLocality": "渋谷区",
"addressRegion": "東京都",
"postalCode": "151-0053",
"addressCountry": "JP"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": "35.6887",
"longitude": "139.6997"
},
"telephone": "+81-3-6276-4579",
"url": "https://www.contencial.co.jp/",
"openingHoursSpecification": [
{
"@type": "OpeningHoursSpecification",
"dayOfWeek": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday"],
"opens": "10:00",
"closes": "19:00"
}
]
}OrganizationとPersonでエンティティ情報を明示する
Organizationタイプは企業や団体の情報を、Personタイプは個人の情報を構造化します。これらのタイプは、コーポレートサイトのトップページや著者紹介ページで特に重要です。Googleのナレッジパネルにも、これらの構造化データが活用されることがあります。
Organizationには、name(組織名)、url(公式サイト)、logo(ロゴ画像)、sameAs(SNSアカウントなど同一エンティティを示すURL)、contactPoint(問い合わせ先)などのプロパティがあります。企業サイトではfounders(創業者)、foundingDate(設立日)、numberOfEmployees(従業員数)なども記述できます。
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "株式会社コンテンシャル",
"url": "https://www.contencial.co.jp",
"logo": "https://www.contencial.co.jp/logo.png",
"foundingDate": "2012-06-26",
"founders": [
{
"@type": "Person",
"name": "柏崎剛"
}
],
"numberOfEmployees": {
"@type": "QuantitativeValue",
"value": 10
},
"sameAs": [
"https://www.facebook.com/profile.php?id=100068984096581",
"https://www.linkedin.com/company/76543602/"
],
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+81-3-6276-4579",
"contactType": "customer service",
"availableLanguage": [
"Japanese"
]
}
}Personタイプには、name(氏名)、jobTitle(職業)、worksFor(勤務先)、alumniOf(出身校)、sameAs(SNSアカウント)などがあります。著者情報としてArticleやBlogPostingと組み合わせて使用することで、E-E-A-T(経験、専門性、権威性、信頼性)の観点からも効果的です。
{
"@context": "https://schema.org",
"@type": "Person",
"name": "柏崎剛",
"alternateName": "かしわざき つよし",
"givenName": "剛",
"familyName": "柏崎",
"birthDate": "1979-09-17",
"birthPlace": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"addressLocality": "杉並区",
"addressRegion": "東京都",
"addressCountry": "JP"
}
},
"jobTitle": [
"代表取締役",
"SEOコンサルタント",
"プログラマ",
"発明家",
"研究家"
],
"worksFor": [
{
"@type": "Organization",
"name": "株式会社コンテンシャル",
"url": "https://www.contencial.co.jp/",
"jobTitle": "代表取締役"
},
{
"@type": "Organization",
"name": "株式会社デブリ",
"url": "https://www.debris.co.jp/",
"jobTitle": "取締役"
}
],
"alumniOf": {
"@type": "EducationalOrganization",
"name": "専門学校東京テクニカルカレッジ",
"department": "情報処理科"
},
"knowsAbout": [
"SEO対策",
"Webマーケティング",
"プログラミング",
"Perl",
"PHP",
"Python",
"UNIX",
"Linux"
],
"award": [
"特許JP7462198(キーワード収集方法)",
"特許JP7479023(コンテンツの生成方法)",
"特許JP7525125(コンテンツの生成方法)",
"特許JP7525128(情報処理方法)",
"特許JP6937952(宣伝管理システム)",
"特許JP6275685(Webページ作成処理プログラム)",
"商標登録「再検索キーワード®」(第6620671号)"
],
"author": [
{
"@type": "Book",
"name": "SEO×生成AI 黄金の教本",
"publisher": "技術評論社",
"isbn": "978-4-297-14911-6"
},
{
"@type": "Book",
"name": "目からウロコのSEO対策「真」常識",
"publisher": "幻冬舎",
"isbn": "978-4-344-93651-5"
}
],
"sameAs": [
"https://www.tsuyoshikashiwazaki.jp/",
"https://twitter.com/tkashiwazaki2",
"https://www.linkedin.com/in/柏崎剛/",
"https://github.com/TsuyoshiKashiwazaki",
"https://www.facebook.com/tys.kashiwazaki",
"https://www.instagram.com/seo_seo_google/",
"https://www.youtube.com/channel/UCZHFqF56PjVaBEMBIWzh1yg",
"https://note.com/tkashiwazaki"
],
"url": "https://www.tsuyoshikashiwazaki.jp/profile/",
"image": "https://www.tsuyoshikashiwazaki.jp/wp-content/uploads/2024/02/柏崎剛近影-300x300.png"
}E-E-A-Tシグナルの強化において、著者情報の構造化データは重要な役割を果たします。以下のプラグインは、Person/Organization/Corporationの3種類の著者タイプを管理し、Article/NewsArticle/BlogPosting/WebPageの各スキーマと連携したJSON-LDマークアップを自動生成します。40以上のSNSアイコンにも対応し、著者のオンラインプレゼンスを包括的に表現できます。
BreadcrumbListでサイト構造を伝える
パンくずリストは、ユーザーが現在地を把握し、上位階層へ移動するためのナビゲーション要素です。BreadcrumbListタイプを使って構造化することで、検索結果のURLの代わりにパンくずリストが表示されるようになります。これにより、ユーザーはクリック前にページの階層位置を理解でき、サイト構造の把握にも役立ちます。
BreadcrumbListは、itemListElementプロパティの配列としてListItemオブジェクトを持ちます。各ListItemにはposition(順序)、name(表示名)、item(URL)を指定します。positionは1から始まり、ルートから現在のページまでの階層を順番に記述します。
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "ホーム",
"item": "https://example.com/"
},
{
"@type": "ListItem",
"position": 2,
"name": "SEO対策",
"item": "https://example.com/seo/"
},
{
"@type": "ListItem",
"position": 3,
"name": "構造化データ",
"item": "https://example.com/seo/structured-data/"
}
]
}BreadcrumbListスキーマの実装では、URLスクレイピングによる各階層タイトルの自動取得が課題となります。以下のプラグインは、実際のURL構造から階層を自動構築し、301/302リダイレクトの追跡や404エラー検出も行いながらJSON-LD構造化データを生成します。最大10階層まで対応し、24時間キャッシュによるパフォーマンス最適化も実現しています。
WebSiteとSearchActionでサイト検索ボックスを表示する
WebSiteタイプとSearchActionを組み合わせることで、検索結果にサイト内検索ボックスを表示できます。ユーザーはGoogleの検索結果から直接そのサイト内を検索でき、目的のページへ素早くアクセスできます。これは特に大規模なサイトや、検索機能が充実したサイトにとって有効な機能です。
この実装には、WebSiteタイプのpotentialActionプロパティにSearchActionオブジェクトを指定します。SearchActionのtargetプロパティでは、検索クエリをパラメータとして受け取るURLテンプレートを記述します。query-inputプロパティで、検索語の入力パラメータ名を指定します。
{
"@context": "https://schema.org",
"@type": "WebSite",
"name": "SEO対策研究室",
"alternateName": "柏崎剛のSEO対策研究室",
"url": "https://www.tsuyoshikashiwazaki.jp/",
"description": "机上の空論を超えた、実践SEO研究",
"inLanguage": "ja",
"publisher": {
"@type": "Organization",
"name": "株式会社コンテンシャル",
"url": "https://www.contencial.co.jp/"
},
"potentialAction": {
"@type": "SearchAction",
"target": {
"@type": "EntryPoint",
"urlTemplate": "https://www.tsuyoshikashiwazaki.jp/?s={search_term_string}"
},
"query-input": "required name=search_term_string"
}
}動画と画像の構造化マークアップを実装する
マルチメディアコンテンツの構造化は、特にYouTubeやGoogleイメージ検索からのトラフィック獲得に重要です。VideoObjectタイプで動画情報を、ImageObjectタイプで画像情報を詳細に記述することで、検索結果での視認性が向上します。動画の場合は、検索結果にサムネイルや再生時間が表示されるようになります。
VideoObjectで動画コンテンツを最適化する
VideoObjectタイプは、Webページに埋め込まれた動画の情報を構造化します。YouTubeやVimeoからの埋め込み動画だけでなく、自社ホスティングの動画にも使用できます。必須プロパティとして、name(タイトル)、description(説明)、thumbnailUrl(サムネイル画像)、uploadDate(公開日)があります。
動画のリッチリザルトでは、サムネイル、再生時間、公開日などが検索結果に表示されます。contentUrl(動画ファイルのURL)やembedUrl(埋め込み用URL)を指定することで、Googleが動画の実体を認識しやすくなります。duration(再生時間)はISO 8601形式で記述し、例えば5分30秒ならPT5M30Sと表記します。
{
"@context": "https://schema.org",
"@type": "VideoObject",
"name": "構造化データの実装方法を解説",
"description": "JSON-LD形式での構造化データ実装手順を、実際の画面を見ながらステップバイステップで解説します。",
"thumbnailUrl": "https://example.com/videos/structured-data-thumb.jpg",
"uploadDate": "2025-01-15T09:00:00+09:00",
"duration": "PT15M30S",
"contentUrl": "https://example.com/videos/structured-data.mp4",
"embedUrl": "https://example.com/embed/structured-data",
"interactionStatistic": {
"@type": "InteractionCounter",
"interactionType": "https://schema.org/WatchAction",
"userInteractionCount": 12500
}
}
ImageObjectで画像の文脈情報を伝える
ImageObjectタイプは、画像の詳細情報を構造化します。通常、画像は他のタイプ(Article、Productなど)のimageプロパティとして使用されることが多いですが、フォトギャラリーや画像が主役のコンテンツでは、独立したImageObjectとしてマークアップすることも有効です。
ImageObjectの主要プロパティには、contentUrl(画像ファイルのURL)、caption(キャプション)、description(説明)、thumbnail(サムネイル)、width(幅)、height(高さ)などがあります。author(撮影者)やcopyrightHolder(著作権者)を指定することで、画像の帰属情報も明確にできます。
{
"@context": "https://schema.org",
"@type": "ImageObject",
"contentUrl": "https://example.com/images/seo-infographic.png",
"caption": "SEO対策の全体像を示したインフォグラフィック",
"description": "検索エンジン最適化の主要な要素と、それぞれの関係性を視覚的に表現した図解",
"width": "1200",
"height": "800",
"author": {
"@type": "Person",
"name": "柏崎剛"
},
"copyrightHolder": {
"@type": "Organization",
"name": "SEO対策研究室"
}
}イベントとレシピの構造化データを活用する
特定の業種やコンテンツタイプでは、専用の構造化データが大きな効果を発揮します。イベント情報サイトではEventタイプが、料理レシピサイトではRecipeタイプが必須と言っても過言ではありません。これらの構造化データは、検索結果での表示を大幅に強化し、ユーザーの行動を直接促すことができます。
Eventでイベント情報を検索結果に表示する
Eventタイプは、コンサート、セミナー、展示会など、特定の日時に開催されるイベントの情報を構造化します。検索結果には、イベント名、開催日時、場所、チケット情報などが表示され、ユーザーは検索結果を見るだけでイベントの基本情報を把握できます。イベント検索専用の検索機能でも、構造化データが活用されています。
Eventの必須プロパティには、name(イベント名)、startDate(開始日時)、location(開催場所)があります。locationには、VirtualLocation(オンライン)、Place(物理的な場所)、またはその両方を指定できます。コロナ禍以降、オンラインイベントやハイブリッドイベントの記述に対応するため、eventAttendanceModeプロパティも追加されました。
{
"@context": "https://schema.org",
"@type": "Event",
"name": "SEO対策実践セミナー2025",
"description": "最新のSEOトレンドと実践的なテクニックを学ぶ1日集中セミナー",
"startDate": "2025-03-15T10:00:00+09:00",
"endDate": "2025-03-15T17:00:00+09:00",
"eventAttendanceMode": "https://schema.org/OfflineEventAttendanceMode",
"eventStatus": "https://schema.org/EventScheduled",
"location": {
"@type": "Place",
"name": "東京国際フォーラム",
"address": {
"@type": "PostalAddress",
"streetAddress": "丸の内3-5-1",
"addressLocality": "千代田区",
"addressRegion": "東京都",
"postalCode": "100-0005",
"addressCountry": "JP"
}
},
"organizer": {
"@type": "Organization",
"name": "SEO対策研究室",
"url": "https://example.com"
},
"offers": {
"@type": "Offer",
"price": "15000",
"priceCurrency": "JPY",
"availability": "https://schema.org/InStock",
"url": "https://example.com/events/seo-seminar-2025/tickets"
}
}Recipeで料理レシピを検索結果に最適化する
Recipeタイプは、料理レシピサイトにとって必須の構造化データです。検索結果には、料理の画像、調理時間、カロリー、評価などがリッチカード形式で表示されます。Googleアシスタントでの音声検索にも、Recipeの構造化データが活用されており、スマートスピーカーでのレシピ読み上げにも対応できます。
Recipeの主要プロパティには、name(料理名)、image(完成写真)、author(レシピ作成者)、prepTime(準備時間)、cookTime(調理時間)、totalTime(合計時間)、recipeYield(分量)、nutrition(栄養成分)、recipeIngredient(材料)、recipeInstructions(手順)などがあります。時間はISO 8601形式で記述します。
{
"@context": "https://schema.org",
"@type": "Recipe",
"name": "本格派カレーライス",
"image": "https://example.com/recipes/curry.jpg",
"author": {
"@type": "Person",
"name": "料理研究家の柏崎剛"
},
"datePublished": "2025-01-10",
"description": "スパイスから作る本格的なカレーライスのレシピ",
"prepTime": "PT30M",
"cookTime": "PT60M",
"totalTime": "PT90M",
"recipeYield": "4人分",
"recipeCategory": "メインディッシュ",
"recipeCuisine": "インド料理",
"nutrition": {
"@type": "NutritionInformation",
"calories": "650 kcal"
},
"recipeIngredient": [
"鶏もも肉 400g",
"玉ねぎ 2個",
"トマト缶 1缶",
"カレー粉 大さじ2"
],
"recipeInstructions": [
{
"@type": "HowToStep",
"text": "玉ねぎをみじん切りにし、きつね色になるまで炒めます"
},
{
"@type": "HowToStep",
"text": "鶏肉を加えて表面に焼き色をつけます"
},
{
"@type": "HowToStep",
"text": "カレー粉を加えて香りが立つまで炒めます"
}
],
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.7",
"reviewCount": "89"
}
}
アプリケーションと書籍と映画の構造化データ
デジタルコンテンツや創作物に関する構造化データも、それぞれの分野で重要な役割を果たしています。SoftwareApplicationタイプはアプリのダウンロードを促進し、Bookタイプは書籍の検索結果を強化し、Movieタイプは映画情報の表示を最適化します。
SoftwareApplicationでアプリ情報を構造化する
SoftwareApplicationタイプは、スマートフォンアプリやデスクトップソフトウェアの情報を構造化します。検索結果には、アプリのアイコン、評価、価格、対応OSなどが表示される可能性があります。App StoreやGoogle Playのアプリページだけでなく、アプリを紹介するWebページでもこのマークアップを使用できます。
主要プロパティには、name(アプリ名)、operatingSystem(対応OS)、applicationCategory(カテゴリー)、offers(価格情報)、aggregateRating(評価)などがあります。MobileApplicationやWebApplicationといったサブタイプも定義されており、より具体的なアプリの種類を示すことができます。
{
"@context": "https://schema.org",
"@type": "SoftwareApplication",
"name": "ConoHa Pencil byGMO",
"url": "https://ai.conoha.jp/pencil/",
"applicationCategory": "BusinessApplication",
"operatingSystem": "Web browser",
"description": "SEOに強いブログ記事をAIで効率的に生成できるライティングツール。キーワード提案から見出し構成、本文生成、リライトまでをサポート。",
"featureList": [
"キーワード提案機能",
"サジェストキーワード調査",
"再検索キーワード調査",
"共起語調査",
"競合見出し調査",
"見出し構成の自動生成",
"本文の自動生成",
"公開済み記事のリライト"
],
"datePublished": "2025-06-26",
"inLanguage": "ja",
"provider": {
"@type": "Organization",
"name": "GMOインターネット株式会社",
"url": "https://internet.gmo/"
},
"creator": {
"@type": "Person",
"name": "柏崎剛",
"affiliation": {
"@type": "Organization",
"name": "株式会社コンテンシャル"
}
},
"offers": [
{
"@type": "Offer",
"name": "Freeプラン",
"price": 0,
"priceCurrency": "JPY",
"description": "月3記事まで無料"
},
{
"@type": "Offer",
"name": "Liteプラン",
"price": 770,
"priceCurrency": "JPY",
"description": "月100クレジット(約12記事)"
}
]
}Bookで書籍情報を詳細に記述する
Bookタイプは、書籍の情報を構造化します。書評サイト、オンライン書店、図書館サイトなどで活用できます。検索結果には、書籍のカバー画像、著者、評価、価格などが表示される可能性があります。電子書籍と紙書籍の両方に対応しており、それぞれの販売情報を別々に記述できます。
Bookの主要プロパティには、name(書名)、author(著者)、isbn(ISBN)、numberOfPages(ページ数)、bookFormat(フォーマット)、offers(販売情報)などがあります。workExampleプロパティを使って、同一タイトルの異なるエディション(ハードカバー、ペーパーバック、電子書籍など)を関連付けることもできます。
{
"@context": "https://schema.org",
"@type": "Book",
"name": "SEO×生成AI 黄金の教本",
"author": [
{
"@type": "Person",
"name": "吉岡智将"
},
{
"@type": "Person",
"name": "柏崎剛"
}
],
"isbn": "978-4-297-14911-6",
"numberOfPages": 399,
"bookFormat": "https://schema.org/Paperback",
"publisher": {
"@type": "Organization",
"name": "技術評論社",
"url": "https://gihyo.jp/"
},
"datePublished": "2025-06-10",
"inLanguage": "ja",
"description": "最新のSEOと生成AIを掛け合わせ、最高の成果を実現する。生成AIの波に立ち向かい、ブログやアフィリエイトサイトが生き残るための86個のトピックを収録。",
"url": "https://gihyo.jp/book/2025/978-4-297-14911-6",
"offers": {
"@type": "Offer",
"price": 2640,
"priceCurrency": "JPY",
"availability": "https://schema.org/InStock",
"url": "https://gihyo.jp/book/2025/978-4-297-14911-6"
}
}Movieで映画情報を構造化する
Movieタイプは、映画の情報を構造化します。映画レビューサイト、動画配信サービス、映画館のWebサイトなどで使用されます。検索結果には、映画のポスター画像、公開年、評価、監督、出演者などが表示される可能性があります。
Movieの主要プロパティには、name(タイトル)、director(監督)、actor(出演者)、datePublished(公開日)、duration(上映時間)、genre(ジャンル)などがあります。aggregateRatingで評価情報を、reviewで個別のレビューを記述できます。
{
"@context": "https://schema.org",
"@type": "Movie",
"name": "SEO戦記",
"director": {
"@type": "Person",
"name": "かしわ監督"
},
"actor": [
{
"@type": "Person",
"name": "かっしー太郎"
},
{
"@type": "Person",
"name": "柏崎つよ子"
}
],
"datePublished": "2025-04-01",
"duration": "PT2H15M",
"genre": ["ドキュメンタリー", "ビジネス"],
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.2",
"reviewCount": "350"
}
}リストとカルーセルとQ&Aページの構造化
複数のアイテムを含むコンテンツや、ユーザー生成のQ&Aコンテンツには、専用の構造化データタイプがあります。ItemListとCarouselはリスト形式のコンテンツに、QAPageはユーザーからの質問と回答のコンテンツに使用します。Datasetは研究データやオープンデータの公開に活用されます。
ItemListとCarouselで一覧コンテンツを最適化する
ItemListタイプは、順序付きまたは順序なしのリストを構造化します。おすすめ商品一覧、ランキング、検索結果一覧などに使用できます。Carouselとして表示される場合、検索結果で横スクロール可能なカード群として表示され、非常に目立つ位置を占めます。
ItemListの主要プロパティには、itemListElement(リストアイテム)、itemListOrder(順序の種類)、numberOfItems(アイテム数)があります。itemListElementの配列には、ListItemオブジェクトを含め、各アイテムのposition(順序)とurl(リンク先)を指定します。各ListItemには、さらに具体的なタイプ(Recipe、Product、Articleなど)をitemプロパティで含めることができます。
{
"@context": "https://schema.org",
"@type": "ItemList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"url": "https://example.com/seo-tools/tool1"
},
{
"@type": "ListItem",
"position": 2,
"url": "https://example.com/seo-tools/tool2"
},
{
"@type": "ListItem",
"position": 3,
"url": "https://example.com/seo-tools/tool3"
}
]
}QAPageでユーザー生成Q&Aを構造化する
QAPageタイプは、ユーザーが質問を投稿し、他のユーザーが回答するタイプのQ&Aページに使用します。FAQPageとの違いは、FAQPageがサイト運営者が用意した質問と回答であるのに対し、QAPageはユーザーコミュニティによる質問と回答を表す点です。Stack OverflowやYahoo!知恵袋のようなサイトに適しています。
QAPageにはmainEntityプロパティでQuestionオブジェクトを指定します。Questionには、name(質問文)、text(質問の詳細)、answerCount(回答数)、upvoteCount(支持数)、dateCreated(投稿日)、author(質問者)、acceptedAnswer(ベストアンサー)、suggestedAnswer(その他の回答)などのプロパティがあります。
{
"@context": "https://schema.org",
"@type": "QAPage",
"mainEntity": {
"@type": "Question",
"name": "JSON-LDとMicrodataはどちらを使うべきですか?",
"text": "構造化データを実装する際、JSON-LDとMicrodataのどちらを選択すべきでしょうか?メリット・デメリットを教えてください。",
"answerCount": 3,
"upvoteCount": 15,
"dateCreated": "2025-01-05",
"author": {
"@type": "Person",
"name": "SEO初心者"
},
"acceptedAnswer": {
"@type": "Answer",
"text": "GoogleはJSON-LDを推奨しています。HTMLと分離できるため、管理が容易で、動的コンテンツにも対応しやすいメリットがあります。",
"upvoteCount": 25,
"dateCreated": "2025-01-06",
"author": {
"@type": "Person",
"name": "SEO専門家"
}
}
}
}Datasetで研究データやオープンデータを公開する
Datasetタイプは、研究データやオープンデータを構造化します。Google Dataset Searchで検索可能になり、研究者やデータアナリストに発見されやすくなります。政府機関、研究機関、企業がデータを公開する際に活用できます。
Datasetの主要プロパティには、name(データセット名)、description(説明)、url(データセットのURL)、distribution(配布形式)、creator(作成者)、datePublished(公開日)、license(ライセンス)などがあります。distributionにはDataDownloadオブジェクトを使用し、ファイル形式やダウンロードURLを指定します。
{
"@context": "https://schema.org",
"@type": "Dataset",
"name": "日本のWebサイトSEO実態調査2025",
"description": "国内主要サイト1000件の構造化データ実装状況を調査したデータセット",
"url": "https://example.com/datasets/seo-survey-2025",
"creator": {
"@type": "Organization",
"name": "SEO対策研究室"
},
"datePublished": "2025-01-20",
"license": "https://creativecommons.org/licenses/by/4.0/",
"distribution": {
"@type": "DataDownload",
"encodingFormat": "text/csv",
"contentUrl": "https://example.com/datasets/seo-survey-2025.csv"
}
}以下に、主要なschema.orgタイプの用途と特徴を一覧で整理します。
| タイプ | 主な用途 | リッチリザルト | 必須プロパティ例 |
|---|---|---|---|
| Article | 記事・コラム | 記事カード | headline, image, author |
| FAQPage | よくある質問 | アコーディオン形式Q&A | mainEntity |
| HowTo | 手順解説 | ステップリスト | name, step |
| Product | 商品情報 | 価格・評価表示 | name, offers |
| LocalBusiness | 店舗情報 | ローカルパック | name, address |
| Event | イベント情報 | イベントリスト | name, startDate, location |
| Recipe | レシピ | レシピカード | name, image, recipeIngredient |
| VideoObject | 動画 | 動画サムネイル | name, thumbnailUrl, uploadDate |
| BreadcrumbList | パンくずリスト | パンくず表示 | itemListElement |
| WebSite | サイト情報 | 検索ボックス | name, url |
構造化データのエラー検出と検証方法
構造化データを実装したら、正しく記述されているかどうかを検証することが重要です。文法エラーや必須プロパティの欠落があると、リッチリザルトが表示されないだけでなく、検索エンジンに誤った情報を伝えてしまう可能性があります。Googleが提供する公式ツールを中心に、効果的な検証方法を解説します。
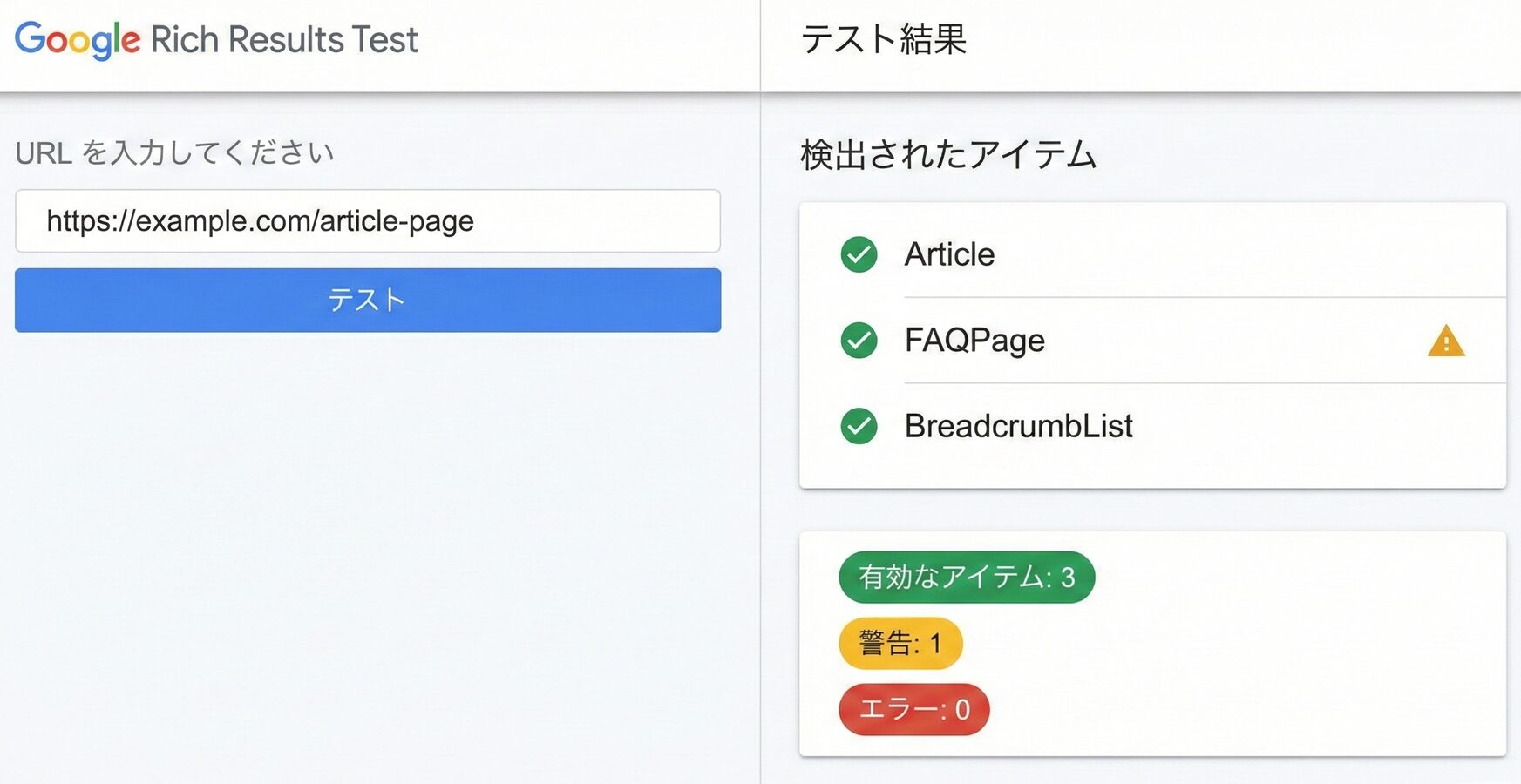
リッチリザルトテストツールの使い方
Googleが提供するリッチリザルトテストは、構造化データの検証に最も頻繁に使用されるツールです。URLを入力するか、HTMLコードを直接貼り付けることで、Googleがどのように構造化データを認識するかを確認できます。検出されたアイテム、エラー、警告がすべて表示され、具体的な修正方法も示されます。
このツールの特徴は、実際のGoogleクローラーと同じ条件でページをレンダリングすることです。JavaScriptで動的に生成される構造化データも、クローラーが認識できる状態で評価されます。また、スマートフォン表示とデスクトップ表示の両方でテストでき、モバイルフレンドリーかどうかも同時に確認できます。
テスト結果では、有効なアイテムは緑色で、警告のあるアイテムは黄色で、エラーのあるアイテムは赤色で表示されます。警告は必須ではないが推奨されるプロパティが欠落している場合に表示され、エラーは必須プロパティの欠落や値の形式エラーで表示されます。エラーがある場合はリッチリザルトが表示されないため、優先的に修正する必要があります。
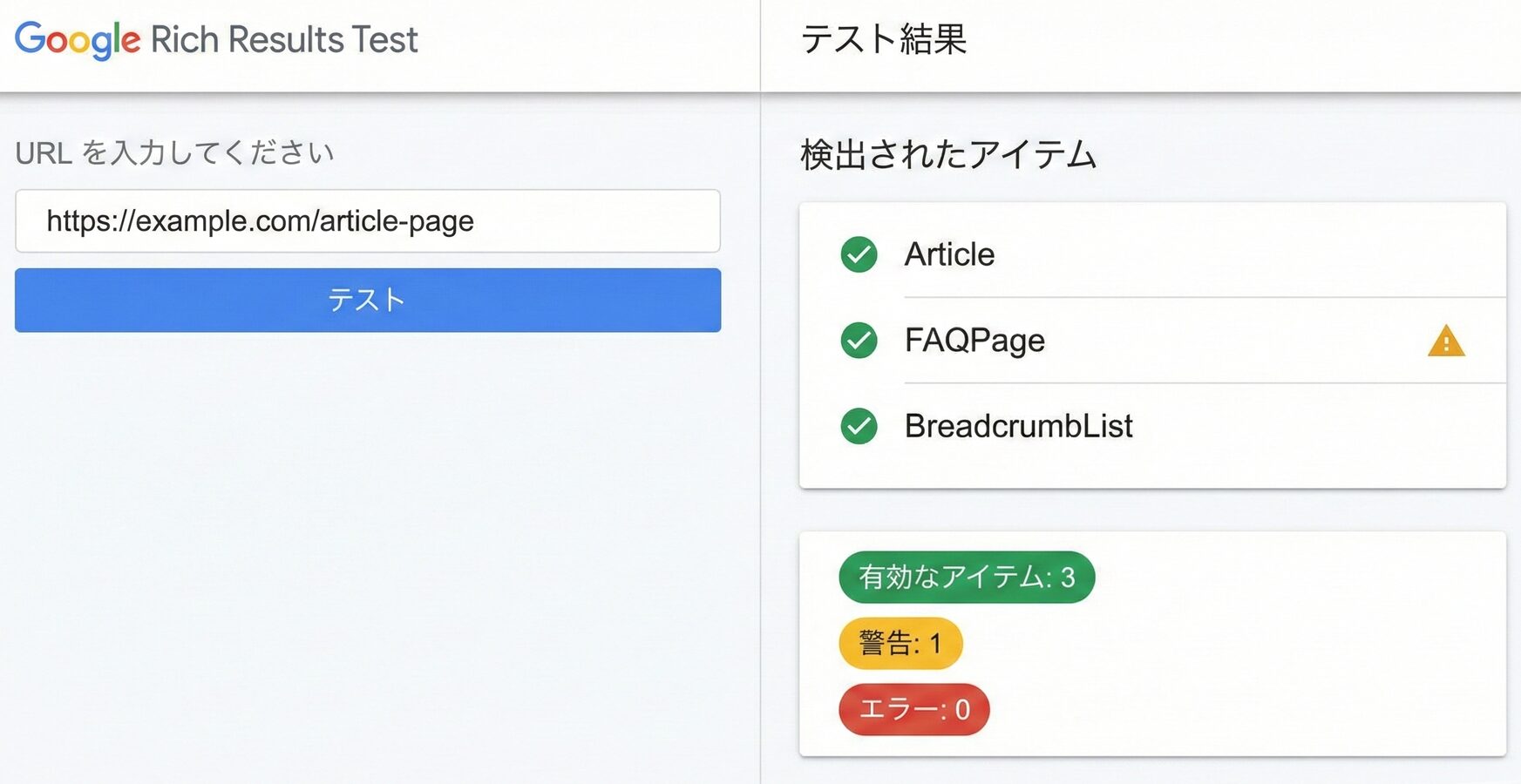
Googleが提供するリッチリザルトテストは、構造化データがリッチリザルトとして表示される資格があるかを確認するための公式ツールです。URLまたはコードを入力することで、検出されたスキーマタイプ、エラー、警告を確認できます。

スキーママークアップ検証ツールの活用
schema.orgが提供するSchema Markup Validatorは、schema.orgの仕様に準拠しているかどうかを検証するツールです。Googleのリッチリザルトテストがリッチリザルト表示の可否に焦点を当てているのに対し、このツールはより広範なスキーマの妥当性を検証します。
このツールでは、Googleがサポートしていないschema.orgタイプも検証できます。schema.orgには数百のタイプが定義されていますが、Googleがリッチリザルトとしてサポートしているのはその一部です。将来的なサポート拡大を見据えて、より詳細なマークアップを実装する場合に活用できます。
検証結果では、構文エラー、未定義のプロパティ、値の型の不一致などが指摘されます。特に、プロパティの値として期待される型(Text、URL、Dateなど)と実際の値が一致しているかどうかを厳密にチェックします。
Google Search Consoleでの継続的なモニタリング
Google Search Consoleの拡張レポートでは、サイト全体の構造化データの状態を継続的にモニタリングできます。構造化データの種類ごとに、有効なアイテム数、警告のあるアイテム数、エラーのあるアイテム数がグラフで表示され、時系列での変化も把握できます。
新しい記事を公開したり、サイトの更新を行った際に、構造化データに問題が発生していないかを定期的に確認することが重要です。Search Consoleでは、問題が検出された場合にメールで通知を受け取ることもでき、早期に対応できます。
特定のエラーをクリックすると、影響を受けているURLの一覧が表示されます。修正を行った後は、URLの検証をリクエストすることで、Googleに再クロールを促すことができます。エラーが解消されると、数日から数週間でリッチリザルトの表示が開始されます。
よくあるエラーパターンとその修正方法
構造化データの実装でよく発生するエラーには、いくつかの典型的なパターンがあります。以下に主要なエラーパターンとその対処法を整理します。
- 必須プロパティの欠落:最も多いエラーです。Productタイプではnameとoffers、Articleタイプではimageが必須です。
- 日時の形式エラー:datePublishedなどはISO 8601形式(例:2025-01-15T09:00:00+09:00)で記述が必要です。タイムゾーンの指定漏れに注意してください。
- URLの形式エラー:imageやurlプロパティには、https://から始まる絶対URLを指定します。相対URLや404を返すURLはエラーの原因となります。
- ネストの構造エラー:括弧の対応ミスやカンマの付け忘れでJSONが無効になります。複雑な構造はJSONバリデータで構文チェックを推奨します。
WordPressで構造化データを実装する方法
WordPressは世界で最も利用されているCMSであり、多くのサイトがWordPressで構築されています。WordPressで構造化データを実装する方法は複数あり、プラグインを使用する方法、テーマを編集する方法、手動でコードを追加する方法があります。サイトの規模や技術力に応じて、最適な方法を選択することが重要です。
プラグインを活用した構造化データの設定
WordPressで構造化データを実装する最も簡単な方法は、専用のプラグインを使用することです。Yoast SEO、Rank Math、All in One SEOといった人気のSEOプラグインには、構造化データ機能が組み込まれています。これらのプラグインを使えば、コードを一切書くことなく、管理画面から構造化データを設定できます。
Yoast SEOでは、各投稿や固定ページの編集画面にスキーマ設定のセクションがあり、コンテンツのタイプ(記事、FAQページ、ハウツーなど)を選択するだけで、適切な構造化データが自動生成されます。サイト全体のOrganization情報やソーシャルプロファイルは、プラグインの設定画面から一括で管理できます。
Rank Mathは、より詳細な構造化データの設定が可能で、スキーマジェネレーター機能を使って、16種類以上のスキーマタイプから選択し、カスタムフィールドの値を動的に埋め込むことができます。条件分岐による自動適用ルールも設定でき、特定のカテゴリーやタグを持つ投稿に自動的に特定のスキーマを適用することが可能です。
汎用SEOプラグインではカバーしきれないコンテンツタイプ固有の構造化データ要件に対応するため、専用プラグインの活用も検討に値します。以下のプラグインは、GoogleのリッチリザルトガイドラインとSchema.org仕様に厳密に準拠したJSON-LDを自動生成し、Article/NewsArticle/BlogPosting/WebPageの4タイプに対応。URL・タイトル・公開日時・更新日時・アイキャッチ画像・著者情報・カテゴリー・タグ・文字数を投稿データから自動取得します。
テーマのfunctions.phpを編集して実装する
より細かいカスタマイズが必要な場合は、テーマのfunctions.phpを編集して構造化データを出力する方法があります。この方法では、WordPressのフックを使って、ページの種類に応じた構造化データを動的に生成できます。プラグインに依存しないため、サイトの軽量化にも寄与します。
wp_headフックを使用して、headタグ内にJSON-LDを出力するのが一般的です。投稿の情報(タイトル、公開日、更新日、アイキャッチ画像、著者など)は、WordPressの関数(get_the_title、get_the_date、get_the_post_thumbnailなど)を使って取得し、JSON形式に組み立てます。
この方法のメリットは、サイト固有の要件に完全に対応できることです。カスタム投稿タイプやカスタムフィールドを使用している場合、それらの値を構造化データに含めることも容易です。ただし、PHPの知識が必要であり、テーマの更新時に上書きされないよう、子テーマを使用することが推奨されます。
手動でHTMLに直接記述する方法
特定のページにのみ構造化データを追加したい場合や、静的なページで変更頻度が低い場合は、手動でHTMLに直接JSON-LDを記述する方法もあります。投稿や固定ページの編集画面で、HTMLモードに切り替えてscriptタグを追加するか、カスタムHTMLブロックを使用します。
この方法は最もシンプルですが、スケーラビリティに欠けます。サイト内の多数のページに構造化データを追加する場合、個別に編集する手間がかかり、一括変更も困難です。また、サイトのリデザインや移行時に、構造化データの移行を別途行う必要があります。
手動記述が適しているのは、トップページや会社概要ページなど、サイト内で1ページしか存在しないユニークなコンテンツです。Organizationスキーマをトップページに追加したり、LocalBusinessスキーマを店舗紹介ページに追加したりする場合に有効です。
WordPressでの構造化データ実装方法には、それぞれメリット・デメリットがあります。以下にそれぞれの方法を比較します。
| 実装方法 | 難易度 | カスタマイズ性 | 保守性 | 推奨ユーザー |
|---|---|---|---|---|
| SEOプラグイン | 低い | 中程度 | 高い | 初心者・中級者 |
| functions.php編集 | 高い | 非常に高い | 中程度 | 開発者 |
| 手動記述 | 中程度 | 高い | 低い | 特定ページのみ対応 |
構造化データのSEO効果と検索結果への影響
構造化データの実装がSEOにどのような効果をもたらすのか、具体的なメリットと期待できる成果について解説します。直接的なランキング要因ではないとされていますが、間接的な効果は非常に大きく、多くのサイトで導入が進んでいます。
リッチリザルトによるクリック率の向上
構造化データの最も直接的なメリットは、リッチリザルトによる検索結果の視認性向上です。通常の検索結果がタイトル、URL、説明文のみで構成されるのに対し、リッチリザルトでは画像、評価、価格、在庫状況など、追加の情報が表示されます。これにより、検索結果ページ上で目立つ位置を占め、ユーザーの注目を集めやすくなります。
Milestone Research社が450万以上のクエリを分析した調査によると、リッチリザルトを持つ検索結果のクリック率は58%であるのに対し、リッチリザルトを持たない検索結果のクリック率は41%でした。特に、FAQリッチリザルトは平均87%という非常に高いクリック率を記録しています。
リッチリザルトの種類によって、表示される検索結果ページ上の位置も異なります。FAQリッチリザルトは、通常の検索結果の下にアコーディオン形式で表示され、検索結果ページ上での占有面積が大きくなります。レシピやハウツーのリッチリザルトは、検索結果上部のカルーセルに表示される場合があり、非常に目立つ位置を獲得できます。
検索エンジンによるコンテンツ理解の精度向上
構造化データを実装することで、検索エンジンがページのコンテンツをより正確に理解できるようになります。これは直接的なランキング要因ではありませんが、適切なクエリに対してページが表示される精度が向上する可能性があります。
例えば、レストランのページにLocalBusinessスキーマを実装し、cuisineTypeプロパティで料理のジャンルを指定すると、「渋谷 イタリアン ランチ」のような複合的なクエリに対して、より適切にマッチングされる可能性が高まります。同様に、Productスキーマで商品のカテゴリーやブランドを明示することで、関連する検索クエリでの表示機会が増える可能性があります。
特に、AIによる検索体験が進化する中で、構造化データの重要性はますます増しています。GoogleのSGE(Search Generative Experience)やBingのCopilotなど、AIが検索結果を要約して提示する機能では、構造化データが参照情報として活用されることがあります。正確な構造化データを実装しておくことで、AI検索での引用可能性も高まります。
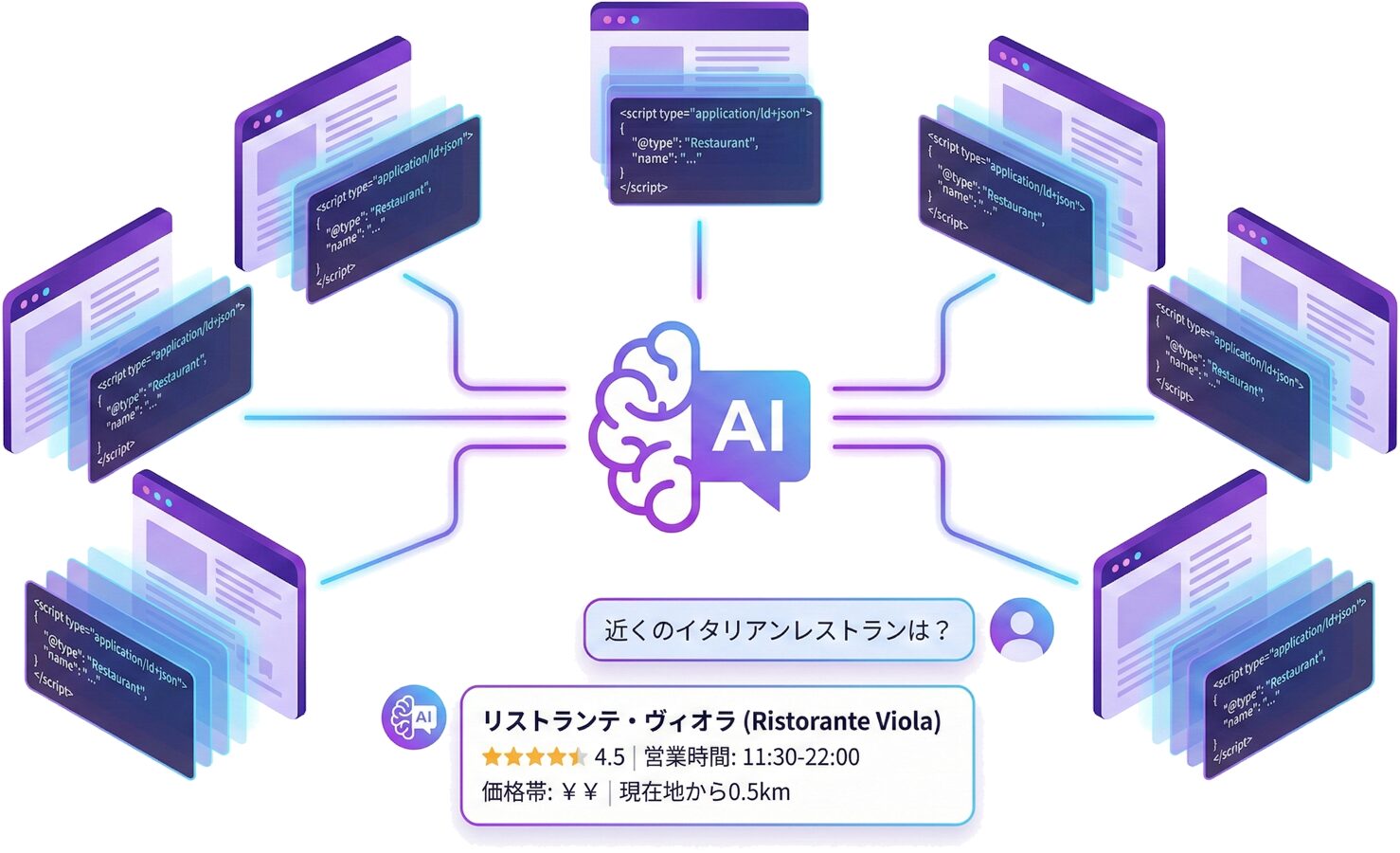
音声検索とスマートデバイスへの対応
音声検索やスマートデバイス(スマートスピーカーなど)からの検索が増加する中、構造化データの役割はさらに重要になっています。音声アシスタントがユーザーの質問に回答する際、構造化データを含むページの情報が優先的に参照される傾向があります。
特に、FAQスキーマとHowToスキーマは音声検索との相性が良いです。「〇〇とは何ですか?」「〇〇のやり方を教えて」といった質問形式のクエリに対して、FAQやHowToの構造化データを持つページが回答ソースとして選ばれやすくなります。
レシピスキーマも音声検索で重要な役割を果たしています。Googleアシスタントでは、Recipeスキーマを持つページの内容を読み上げる機能があり、ユーザーは調理中にハンズフリーでレシピを確認できます。この機能に対応するためには、recipeInstructionsプロパティで手順を明確に記述することが必要です。
構造化データ実装の歴史と将来展望
構造化データとセマンティックWebの概念は、インターネットの黎明期から存在していました。しかし、実用的な形で普及が進んだのは2010年代以降です。その歴史を振り返りながら、今後の展望についても考察します。
セマンティックWebからschema.orgへの進化
セマンティックWebの概念は、World Wide Web(WWW)の発明者であるティム・バーナーズ=リーによって1990年代末に提唱されました。彼のビジョンは、Webページの情報を機械が理解し、自動的に処理できる「意味のあるWeb」の実現でした。この実現に向けて、RDF(Resource Description Framework)やOWL(Web Ontology Language)といった技術標準が策定されました。
しかし、これらの技術は複雑で、一般的なWebサイト開発者にとって敷居が高いものでした。そこで、2011年に主要検索エンジンが共同でschema.orgを立ち上げ、より実用的で使いやすいボキャブラリを提供しました。schema.orgの登場により、構造化データの実装が大幅に簡素化され、普及が加速しました。
JSON-LDの標準化(2014年にW3C勧告)も、普及に大きく貢献しました。それまでのMicrodataやRDFaに比べて、JSON-LDは開発者にとって馴染みのあるJSON形式を採用し、HTMLとの分離を実現したことで、実装の障壁が大幅に下がりました。Googleが2015年以降、JSON-LDを公式に推奨するようになったことも、採用を後押ししました。
現在の普及状況と業界トレンド
現在、大規模なWebサイトの多くが何らかの構造化データを実装しています。WebDataCommonsの2024年10月の調査によると、調査対象24億ページのうち51.25%(約13億ページ)で構造化データが検出されました。2010年の調査ではわずか5.7%だったことを考えると、この10年間で飛躍的に普及が進んだことがわかります。
出典: WebDataCommons
Googleは定期的に新しいリッチリザルトタイプを追加しており、構造化データの活用範囲は拡大し続けています。最近では、求人情報、教育コース、FAQなどのリッチリザルトが追加されました。また、既存のリッチリザルトについても、必須プロパティの追加や仕様変更が行われることがあり、継続的な対応が必要です。
構造化データの実装状況は、SEO監査の重要な項目となっています。競合サイト分析においても、構造化データの実装有無や種類を確認することが一般的です。構造化データを実装していないサイトは、リッチリザルトを獲得している競合に対して不利な状況にあると言えます。
AIと構造化データの融合が示す未来
生成AIの急速な発展は、構造化データの未来にも大きな影響を与えています。GoogleのSGEやBingのCopilotに代表されるAI検索では、Webページの情報を統合して回答を生成します。この過程で、構造化データは重要な参照情報として活用されています。
AI検索エンジンは、構造化データを通じてページのコンテンツを正確に把握し、より適切な回答を生成できます。例えば、Productスキーマで価格や仕様が構造化されていれば、AIは複数の商品を正確に比較して提示できます。FAQスキーマで質問と回答が構造化されていれば、AIはその情報を直接引用して回答できます。
将来的には、さらに高度な構造化データの活用が予想されます。AIエージェントがユーザーに代わってWebサイトを操作する時代が来れば、構造化データはエージェントがサイトの機能を理解するための重要な手がかりとなります。予約システムや購入フローを構造化データで記述することで、AIエージェントがそれらの機能を自動的に利用できるようになる可能性があります。
構造化データ実装でよくある誤解と正しい理解
構造化データに関しては、いくつかの誤解が広まっています。これらの誤解を解消し、正しい理解に基づいた実装を行うことが、効果的なSEOにつながります。
構造化データは直接的なランキング要因ではない
最も一般的な誤解は、構造化データを実装すれば検索順位が直接上がるというものです。Googleは公式に、構造化データは直接的なランキング要因ではないと明言しています。つまり、同じ内容のページがあった場合、構造化データの有無だけで順位が決まることはありません。
ただし、間接的な効果は確実にあります。リッチリザルトによるクリック率の向上、ブランド認知の向上、ユーザーエンゲージメントの改善などが、長期的にはサイトの評価向上につながる可能性があります。また、構造化データを適切に実装することで、検索エンジンがコンテンツを正確に理解し、適切なクエリに対してページを表示しやすくなります。
重要なのは、構造化データを「SEOの裏技」として捉えるのではなく、検索エンジンとユーザーの両方に対して、コンテンツを正確に伝えるための手段として捉えることです。質の高いコンテンツがあってこそ、構造化データは効果を発揮します。
すべてのページに構造化データが必要なわけではない
構造化データは、すべてのページに必要なわけではありません。リッチリザルトとしてサポートされているタイプのコンテンツがあるページ、または検索エンジンに特定の情報を明示的に伝えたいページに実装すれば十分です。
例えば、お問い合わせページや利用規約ページに構造化データを実装しても、リッチリザルトが表示されることはほとんどありません。これらのページに時間をかけて構造化データを実装するよりも、商品ページやブログ記事など、SEO効果が期待できるページに注力すべきです。
サイト全体でBreadcrumbListやWebSiteは一括で実装する価値がありますが、すべてのページに詳細な構造化データを実装する必要はありません。投資対効果を考慮し、優先順位を付けて実装を進めることが重要です。
リッチリザルトの表示は保証されない
構造化データを正しく実装しても、リッチリザルトの表示が保証されるわけではありません。Googleは、リッチリザルトを表示するかどうかを、さまざまな要因に基づいてアルゴリズムで判断しています。構造化データの実装は必要条件ですが、十分条件ではありません。
リッチリザルトが表示されない理由としては、サイトの信頼性が低いと判断されている、検索クエリとの関連性が低い、同じ検索結果に多数のリッチリザルトが表示されるとユーザー体験を損なうとGoogleが判断している、などがあります。また、Googleのポリシーに違反している構造化データは、マニュアルアクションの対象となり、リッチリザルトが表示されなくなる可能性があります。
構造化データを実装する際は、Googleのガイドラインに厳密に従うことが重要です。特に、ページに表示されていない情報を構造化データに含めること(例:実際には100件のレビューがないのにreviewCount:100と記述する)は、スパム行為とみなされる可能性があります。
Googleは構造化データに関するガイドラインと技術ドキュメントを公式に提供しています。各スキーマタイプの必須プロパティ、推奨プロパティ、実装例、よくある問題の解決方法などが詳細に説明されています。

構造化データに関する用語解説と基礎知識
構造化データに関連する専門用語は多く、初めて学ぶ方にとっては混乱しやすい分野です。ここでは、重要な用語とその意味を整理し、基礎知識として押さえておくべきポイントを解説します。
基本用語の定義と相互関係
構造化データとは、特定の形式で整理され、機械が読み取りやすくなったデータのことです。Webの文脈では、Webページの情報を検索エンジンが理解しやすい形式で記述したデータを指します。構造化マークアップは、この構造化データをHTMLに埋め込む作業またはその記述方法を指し、両者はほぼ同義で使用されます。
schema.orgは、構造化データを記述するためのボキャブラリ(語彙集)を提供するプロジェクトです。数百のタイプと数千のプロパティが定義されており、主要な検索エンジンすべてが認識しています。タイプは構造化する対象の種類(Person、Product、Articleなど)を表し、プロパティはその対象の属性(name、price、datePublishedなど)を表します。
JSON-LD、Microdata、RDFaは、schema.orgのボキャブラリを使って構造化データを記述するための形式(シンタックス)です。内容は同じでも、記述方法が異なります。Googleは公式にJSON-LDを推奨しています。
リッチリザルトとリッチスニペットの違い
リッチリザルトとリッチスニペットは、しばしば混同される用語です。リッチスニペットは、検索結果の通常のスニペット(タイトル、URL、説明文)に追加の情報(評価、価格など)が付加されたものを指す、古い呼び方です。
リッチリザルトは、より広い概念で、リッチスニペットを含む検索結果上の拡張表示全般を指します。主なリッチリザルトの種類には以下のものがあります。
- FAQの展開表示(アコーディオン形式でQ&Aが表示される)
- レシピのカード表示(調理時間、カロリー、評価などが表示される)
- イベントのリスト表示(開催日時、場所、チケット情報が表示される)
- 商品の価格・評価表示(価格、在庫状況、レビュー評価が表示される)
現在、Googleはリッチリザルトという用語を公式に使用しています。
リッチリザルトの種類は多岐にわたり、検索クエリやコンテンツの種類によって表示形式が異なります。同じProductスキーマでも、検索結果の通常のリストに価格と評価が追加表示される場合もあれば、上部のショッピング広告枠に表示される場合もあります。
エンティティとナレッジグラフの概念
エンティティとは、現実世界に存在する「もの」や「概念」を指します。人物、場所、組織、イベント、製品など、固有の実体を持つものがエンティティです。検索エンジンは、Webページ上の文字列をエンティティとして認識し、その関係性を理解しようとしています。
ナレッジグラフは、エンティティとその関係性をグラフ構造で表現したデータベースです。Googleは独自のナレッジグラフを構築しており、検索結果の右側に表示されるナレッジパネルは、ナレッジグラフの情報を元に生成されています。
構造化データは、ナレッジグラフの精度向上に貢献しています。Webページに記述された構造化データは、Googleがエンティティを認識し、他のエンティティとの関係性を理解する手助けとなります。特にOrganizationやPersonスキーマの情報は、ナレッジグラフに直接反映される可能性があります。
構造化データ実装のベストプラクティス
構造化データを効果的に実装するためのベストプラクティスをまとめます。これらの原則に従うことで、エラーを防ぎ、最大限の効果を得ることができます。
一貫性と正確性を維持する
構造化データの内容は、ページに表示されている情報と完全に一致させる必要があります。例えば、ページ上で価格が「9,800円」と表示されているなら、Productスキーマのpriceプロパティも同じ値を記述します。ページと構造化データの内容が異なると、Googleのポリシー違反となる可能性があります。
また、サイト全体で構造化データの実装に一貫性を持たせることも重要です。同じタイプのページには同じ構造のスキーマを使用し、プロパティの記述方法も統一します。著者情報の記述方法、日時のフォーマット、URLの形式などを標準化しておくことで、管理が容易になります。
定期的なメンテナンスも欠かせません。サイトの内容が更新されたら、構造化データも同時に更新する必要があります。特に価格、在庫状況、イベント日時など、頻繁に変わる情報は、リアルタイムでの更新が求められます。
必須プロパティを確実に含める
各スキーマタイプには、Googleが定める必須プロパティがあります。これらを欠落させると、リッチリザルトが表示されなくなります。Googleの公式ドキュメントで、使用するスキーマタイプの必須プロパティを事前に確認し、すべて含めるようにしてください。
推奨プロパティも、可能な限り含めることが望ましいです。推奨プロパティを追加することで、リッチリザルトにより多くの情報が表示される可能性が高まり、ユーザーへの訴求力が向上します。ただし、情報がない場合に架空の値を入れることは絶対に避けてください。
スキーマの仕様は定期的に更新されるため、必須プロパティや推奨プロパティが変更されることがあります。Search Consoleでエラーが検出された場合は、最新のGoogleドキュメントを確認し、必要に応じてマークアップを更新してください。
複数のスキーマタイプを適切に組み合わせる
1つのページに複数のスキーマタイプを含めることは、一般的であり推奨される場合もあります。例えば、ブログ記事のページには、ArticleスキーマとBreadcrumbListスキーマ、さらにWebSiteスキーマを含めることが適切です。各スキーマは独立したJSON-LDブロックとして記述することも、1つのJSON-LD内に@graphプロパティで複数のアイテムを含めることもできます。
ネストによる関連付けも効果的です。ArticleスキーマのauthorプロパティにPersonスキーマを含めたり、ProductスキーマのoffersプロパティにOfferスキーマを含めたりすることで、情報間の関係性を明示できます。ただし、過度に複雑なネストは避け、読みやすさと保守性を考慮した構造にしてください。
スキーマタイプの選択に迷った場合は、より具体的なサブタイプを選ぶことが推奨されます。例えば、レストランのページにはLocalBusinessよりもRestaurantを使用し、ブログ記事にはArticleよりもBlogPostingを使用します。
まとめとして構造化データの実践に向けて
構造化データと構造化マークアップは、現代のSEOにおいて欠かせない技術となっています。検索エンジンにコンテンツの意味を正確に伝え、リッチリザルトによってユーザーの注目を集めることで、サイトのトラフィック向上に貢献します。
実装を始めるにあたっては、まず自サイトのコンテンツを分析し、どのスキーマタイプが適しているかを判断してください。サイトタイプ別の推奨スキーマは以下の通りです。
- ECサイト: ProductとOffer(商品情報、価格、在庫状況)
- メディアサイト: ArticleとBreadcrumbList(記事情報、サイト構造)
- 地域ビジネス: LocalBusiness(店舗情報、営業時間、連絡先)
- 企業サイト: OrganizationとWebSite(企業情報、サイト検索)
次に、Googleのリッチリザルトテストツールで検証しながら、段階的に実装を進めていくことを推奨します。
構造化データは一度実装して終わりではなく、継続的なメンテナンスが必要です。Google Search Consoleで定期的に状態を確認し、エラーが発生したら速やかに対応してください。また、Googleの仕様変更に追従するため、公式ブログやドキュメントをチェックする習慣をつけることも重要です。
構造化データの実装は技術的な作業ですが、その本質は「コンテンツの価値を正しく伝える」ことにあります。質の高いコンテンツがあってこそ、構造化データは効果を発揮します。コンテンツの品質向上と構造化データの最適化を両輪として、SEO戦略を進めていただければと思います。
よくある質問
SEO Note! Team (SEO施策スタッフ)
SEOエンジニア、マーケター、ライター、編集担当からなる専門チームです。技術的なサイト最適化からコンテンツ戦略の立案、記事の執筆・編集まで、SEO施策を一気通貫で対応できる体制を整えています。10万パターン以上のキーワード対策と3万を超えるドメインの運用で培った実践的なノウハウをもとに、机上の理論だけでは得られない現場視点のSEO支援を提供しています。
関連記事




