
Webサイトを運営していると「クローラー」や「インデックス」という言葉を耳にする機会が増えてきます。これらは検索エンジンが世界中のWebページを収集し、検索結果に表示するための根幹を成す仕組みです。しかし、この2つの言葉を混同している方や、具体的にどのような処理が行われているのか理解していない方も少なくありません。この記事では、クローラーとインデックスの違いから、Googleに正しくインデックスされるための実践的な方法まで、初心者の方にもわかりやすく解説していきます。SEOの基礎を固めたい方から、すでに実務に携わっている担当者の方まで、幅広い層に役立つ情報をお届けします。
なお、世界の検索エンジン市場ではGoogleが圧倒的なシェアを占めています。Statcounter Global Stats(2025年11月)のデータによると、Googleのシェアは約90%に達しており、SEO対策を考える上でGoogleのクローラーとインデックスの仕組みを理解することが極めて重要です。
クローラーの仕組みと役割を理解する
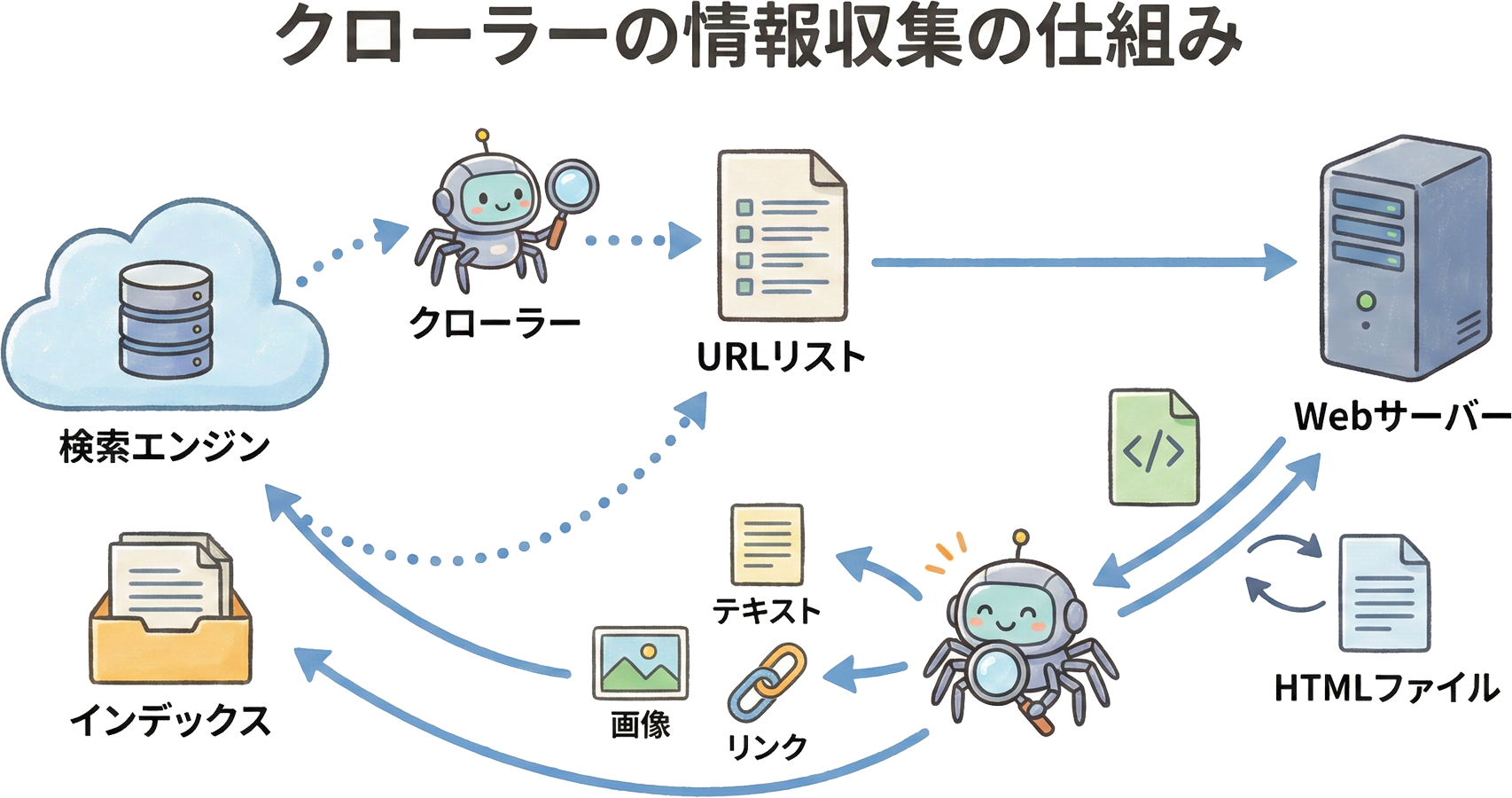
クローラーとは、検索エンジンがWebサイトの情報を収集するために使用する自動プログラムのことです。Googleの場合、このプログラムは「Googlebot」と呼ばれており、インターネット上を絶え間なく巡回しています。クローラーは、まるでインターネットという広大な図書館を巡る司書のような存在で、新しいページの発見や既存ページの更新情報を収集する役割を担っています。検索エンジンがユーザーに適切な検索結果を提供するためには、まずWebページの情報を把握する必要があり、その第一歩がクローラーによる情報収集なのです。
クローラーという名前は、「這う」という意味の英語「crawl」に由来しています。これは、クローラーがリンクを1つずつたどりながらWeb上を移動する様子を表現しています。Googlebot以外にも、Bingbot(Microsoft)、Yandex Bot(ロシア)、Baidu Spider(中国)など、各検索エンジンが独自のクローラーを運用しています。また、クローラーにはデスクトップ版とモバイル版があり、現在のGoogleはモバイル版のGooglebotを主に使用してクロールを行っています。これはモバイルファーストインデックスの方針に基づくもので、スマートフォンでの表示を優先的に評価するためです。
クローラーがWebページを発見する流れ
クローラーがあなたのWebサイトを発見する方法はいくつかあります。最も一般的なのは、他のWebサイトからのリンクをたどってやってくるパターンです。すでにGoogleに認識されているサイトからリンクが張られていると、クローラーはそのリンクを発見し、あなたのサイトにたどり着きます。この仕組みがあるからこそ、SEOにおいて被リンク(外部リンク)の獲得が重要視されているのです。新しいサイトや新しいページを作成した場合、どこからもリンクされていないとクローラーに発見されにくくなります。
また、XMLサイトマップを送信することで、クローラーに直接ページの存在を知らせることも可能です。XMLサイトマップとは、サイト内のURLを一覧にしたファイルで、Google Search Consoleから送信できます。これにより、リンクがない新規ページでも、クローラーに効率的に認識してもらえるようになります。さらに、Google Search Consoleを使用して手動でURL検査をリクエストする方法もあります。これらの経路を通じて、クローラーは日々膨大な数のページを発見し続けています。
クローラーがWebページを発見する主な経路をまとめると、以下のようになります。
- 他のWebサイトからの外部リンクをたどる
- XMLサイトマップを通じて直接URLを認識する
- Google Search ConsoleからのURL検査リクエスト
- 内部リンクをたどってサイト内を巡回する
クローラーが収集する情報の内容
クローラーがWebページにアクセスすると、そのページのHTMLコードを取得します。この中には、ページのタイトル、見出し、本文、画像の代替テキスト、内部リンク、外部リンクなど、あらゆる情報が含まれています。クローラーはHTMLの構造を解析し、ページがどのようなトピックについて書かれているのか、どのような情報を提供しているのかを理解しようとします。特に、titleタグ、metaタグ、見出しタグ(h1〜h6)、本文のテキストは重要な評価対象となります。
また、ページの読み込み速度やモバイル対応状況といった技術的な要素も評価対象となります。Core Web Vitalsと呼ばれる指標(LCP、FID、CLS)も、クローラーが収集する重要な情報の一つです。クローラーはこれらの情報を持ち帰り、後の処理に備えて整理します。ただし、JavaScriptで動的に生成されるコンテンツについては、レンダリングという追加の処理が必要となる場合があり、すべての情報が即座に取得されるわけではない点に注意が必要です。JavaScriptに依存したサイトでは、クローラーがコンテンツを正しく認識できるよう、サーバーサイドレンダリング(SSR)や事前レンダリングなどの対策を検討することが推奨されます。

インデックスの役割と検索結果への影響
インデックスとは、クローラーが収集した情報をGoogleのデータベースに登録する処理、およびそのデータベース自体を指す言葉です。書籍でいうところの「索引」に相当し、検索エンジンが適切な検索結果を素早く返すための重要な仕組みとなっています。Googleは世界中の何十億ものWebページの情報をインデックスとして保存しており、ユーザーが検索クエリを入力すると、このインデックスから関連性の高いページを瞬時に見つけ出して表示しています。
インデックスは単なるURLの一覧ではありません。各ページのコンテンツ内容、キーワードの出現頻度、リンク関係、更新日時、モバイル対応状況など、多くの情報が構造化されて保存されています。これにより、検索エンジンは「このキーワードに最も関連性が高いページはどれか」「この質問に対する最適な回答を含むページはどれか」といった判断を高速に行うことができます。インデックスの品質と規模が、検索エンジンの性能を大きく左右するといっても過言ではありません。
インデックスされることの重要性
どれほど素晴らしいコンテンツを作成しても、インデックスされていなければ検索結果に表示されることはありません。インデックスは検索エンジンの図書館に本を登録するようなもので、登録されていない本は読者が探すことができないのと同じです。逆に言えば、インデックスされることで初めて、検索ユーザーがあなたのコンテンツを発見できる可能性が生まれます。そのため、新しいページを公開した後は、そのページがインデックスされているかどうかを確認することがSEOの基本的な作業となります。
インデックスされることの重要性は、特にビジネスサイトやECサイトにおいて顕著です。新商品のページがインデックスされていなければ、その商品を検索しているユーザーに見つけてもらえません。また、ニュースサイトやブログでは、記事の公開後いかに早くインデックスされるかが、検索からの流入数に直結します。競合他社より先にインデックスされることで、検索結果での優位性を確保できる場合もあります。このように、インデックスの有無や速度は、Webサイトの集客力に直接的な影響を与える重要な要素なのです。
クローラーとインデックスの違いを明確に理解する
クローラーとインデックスは密接に関連していますが、明確に異なる概念です。クローラーは「情報を収集するプログラム」であり、インデックスは「情報を登録・保存する処理とデータベース」です。クローラーが巡回したからといって、必ずしもインデックスされるわけではありません。クローラーはページの内容を評価し、検索結果に表示する価値があると判断した場合にのみインデックスを行います。低品質なコンテンツや重複コンテンツは、クローラーに発見されてもインデックスから除外される可能性があります。この違いを理解することが、効果的なSEO施策の第一歩です。
両者の違いを整理すると、次の表のようになります。
| 項目 | クローラー | インデックス |
|---|---|---|
| 役割 | 情報を収集する | 情報を登録・保存する |
| 本質 | 自動プログラム(ロボット) | データベースと登録処理 |
| 比喩 | 図書館を巡回する司書 | 図書館の蔵書目録 |
| 処理順序 | 先に実行される | クロール後に実行される |
| 成功条件 | ページにアクセスできること | 品質基準を満たすこと |

検索エンジンにインデックスされるまでの全体像
Webページが検索結果に表示されるまでには、複数のステップを経る必要があります。このプロセスを理解することで、どの段階で問題が発生しているのかを特定しやすくなります。SEOの施策を行う際には、単に「検索結果に表示されない」という現象だけを見るのではなく、発見・クロール・処理・インデックスのどの段階に問題があるのかを切り分けて考えることが重要です。
たとえば、ページが検索結果に表示されない原因として、robots.txtでクローラーのアクセスがブロックされている場合(発見・クロールの問題)、noindexタグが設定されている場合(インデックスの問題)、コンテンツの品質が低いと判断されている場合(品質評価の問題)など、様々なケースが考えられます。原因によって対処法も異なるため、全体像を把握しておくことが効果的な改善につながります。
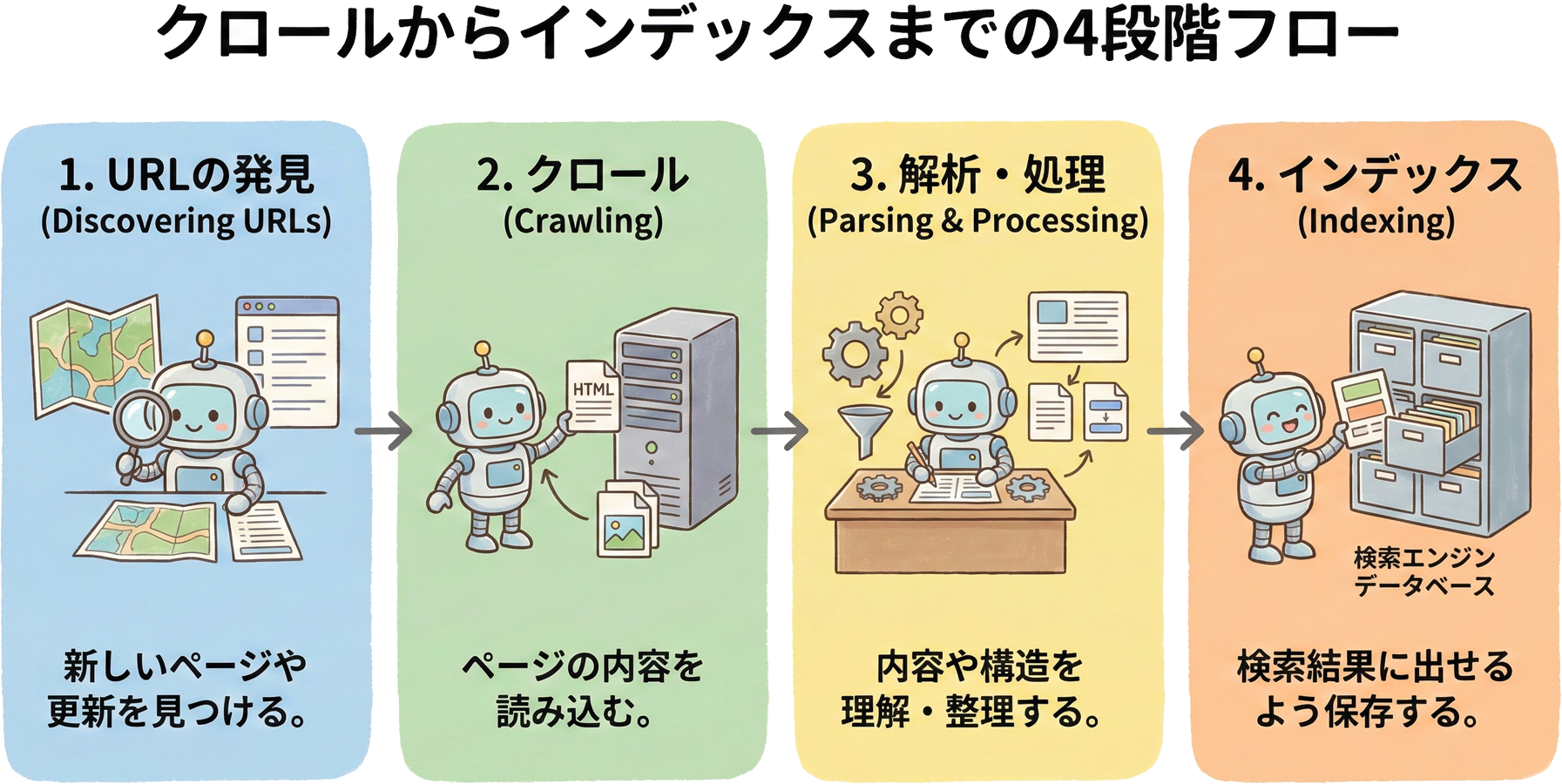
クロールからインデックスまでの4段階
検索エンジンがWebページを処理する流れは、大きく4つの段階に分けられます。最初の段階は「発見」です。クローラーがリンクやサイトマップを通じてページのURLを発見します。次の段階は「クロール」で、発見したURLにクローラーがアクセスし、ページの内容を取得します。3番目の段階は「処理」であり、取得したHTMLを解析し、JavaScriptのレンダリングが必要な場合はその処理も行います。最後の段階が「インデックス」で、処理された情報がGoogleのデータベースに登録されます。これらすべての段階を経て初めて、検索結果にページが表示される可能性が生まれるのです。
この4段階のプロセスを順番に整理すると、以下の流れになります。
- 発見(Discovery):リンクやサイトマップを通じてURLを認識
- クロール(Crawl):発見したURLにアクセスしてHTMLを取得
- 処理(Processing):HTMLの解析とJavaScriptのレンダリング
- インデックス(Index):品質評価を経てデータベースに登録
インデックス完了までにかかる時間の目安
新しいページがインデックスされるまでの時間は、状況によって大きく異なります。すでにGoogleから高い評価を受けているサイトの場合、数時間から数日程度でインデックスされることも珍しくありません。大手ニュースサイトや頻繁に更新される人気ブログでは、新しい記事が公開されてから数分〜数時間でインデックスされることもあります。これは、Googleがそのサイトを信頼し、高頻度でクロールを行っているためです。
一方、新規サイトやあまり更新頻度の高くないサイトでは、数週間から数ヶ月かかる場合もあります。特に、まだGoogleに認識されていない新規ドメインでは、最初のインデックスに時間がかかることが一般的です。また、サイトの規模や技術的な問題の有無、コンテンツの品質なども影響要因となります。インデックスを早めるためには、定期的なコンテンツ更新、適切な内部リンク構造、XMLサイトマップの送信などが効果的とされています。Google Search Consoleのカバレッジレポートを定期的に確認し、クロールやインデックスの状況を監視することも重要です。
Google Search Consoleを使ったインデックス登録の方法
Google Search Consoleは、Webサイト運営者にとって欠かせない無料ツールです。このツールを活用することで、インデックス状況の確認から登録リクエストまで、さまざまな操作を行うことができます。Search Consoleは、Googleがあなたのサイトをどのように認識しているかを確認できる唯一の公式ツールであり、SEO対策において必須のダッシュボードとなっています。
Search Consoleでは、インデックス状況の確認以外にも、検索パフォーマンス(表示回数、クリック数、平均掲載順位)の分析、モバイルユーザビリティの問題検出、セキュリティ問題の通知、構造化データのエラー確認など、多くの機能を利用できます。サイトを運営している方は、まずSearch Consoleにサイトを登録し、定期的にデータを確認する習慣をつけることをおすすめします。登録は無料で、ドメイン所有権の確認を行うことで利用開始できます。
URL検査ツールでインデックス状況を確認する
Google Search Consoleにログインし、URL検査ツールを使用すると、特定のページのインデックス状況を詳しく確認できます。画面上部の検索バーに確認したいURLを入力すると、そのページがGoogleにインデックスされているかどうかが表示されます。インデックスされている場合は「URLはGoogleに登録されています」というメッセージが表示され、最後のクロール日時なども確認できます。インデックスされていない場合は、その理由も併せて表示されるため、問題解決の糸口を見つけることができます。
URL検査ツールでは、インデックス状況以外にも、ページのモバイルフレンドリー判定、構造化データの検出状況、ページの読み込み問題なども確認できます。また、「公開URLをテスト」機能を使えば、現在のライブページをGoogleがどのように認識するかをリアルタイムで確認することも可能です。これは、ページを更新した後や、技術的な変更を行った後に、問題がないかを確認するのに役立ちます。
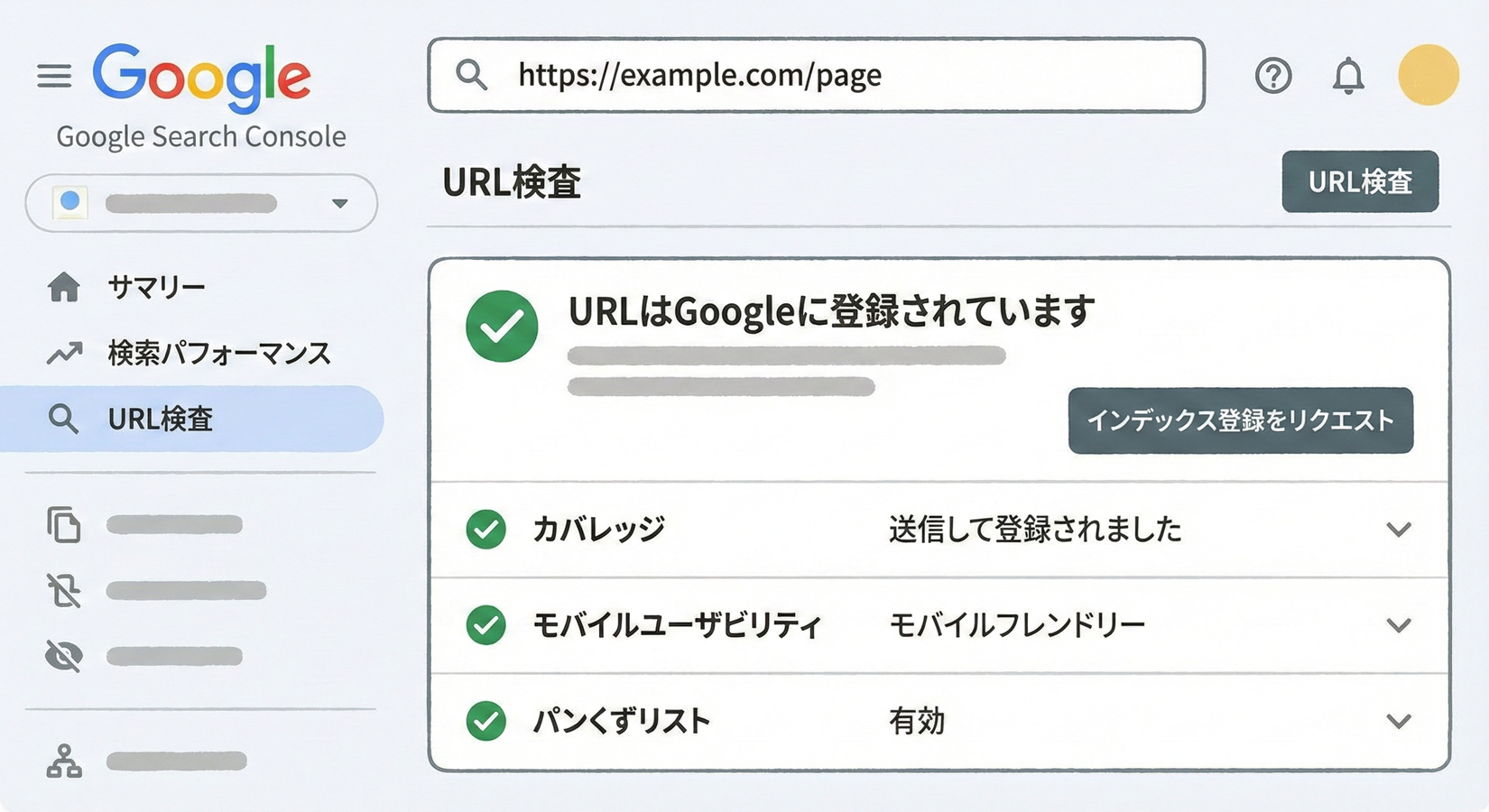
インデックス登録をリクエストする手順
新しいページを公開した際や、大幅な更新を行った際には、インデックス登録のリクエストを送信することをおすすめします。URL検査ツールでページを検索した後、「インデックス登録をリクエスト」というボタンをクリックすることで、Googleにクロールを促すことができます。リクエストを送信すると、Googleはそのページを優先的にクロールキューに追加し、通常より早くクロールを行います。
ただし、このリクエストはあくまでも「優先的にクロールしてほしい」という要望であり、必ずしも即座にインデックスされることを保証するものではありません。ページの品質が低い、重複コンテンツがある、技術的な問題があるなどの理由でインデックスが見送られる場合もあります。また、1日にリクエストできる回数には上限があるため、本当に重要なページに絞って使用することが推奨されます。全ページに対してリクエストを送信するのではなく、新規公開したページや、大幅に内容を更新したページに対して使用するようにしましょう。
インデックスされない原因と対処法
せっかく作成したコンテンツがインデックスされないと、大きな機会損失につながります。ここでは、インデックスされない代表的な原因とその対処法、さらに意図的にインデックスを制御する方法について詳しく解説します。インデックスされない原因は技術的な問題からコンテンツの品質問題まで多岐にわたります。原因を正しく特定し、適切な対処を行うことが重要です。
Google Search Consoleのカバレッジレポートでは、インデックスされていないページが「除外」として表示され、その理由も確認できます。「クロール済み – インデックス未登録」「検出 – インデックス未登録」「noindexタグによって除外されました」など、理由によって対処法が異なります。まずはカバレッジレポートで現状を把握し、どのような問題が発生しているかを確認することから始めましょう。
robots.txtによるクロールブロック
robots.txtファイルは、クローラーのアクセスを制御するためのファイルです。このファイルの設定を誤ると、意図せずクローラーのアクセスを遮断してしまうことがあります。特に、サイトリニューアル後やサーバー移転後には、開発環境の設定がそのまま残っているケースが見られます。開発環境では検索エンジンにインデックスされないよう、robots.txtで全体をブロックしていることが多いため、本番環境への移行時にこの設定を解除し忘れると、サイト全体がインデックスされなくなります。
Google Search ConsoleのURL検査ツールを使用すると、robots.txtによってブロックされているかどうかを確認できます。問題がある場合は、robots.txtファイルを修正して、必要なページへのクロールを許可する設定に変更しましょう。また、robots.txtでDisallow設定を行うことで、意図的にクローラーのアクセス自体を制限することも可能です。管理画面やショッピングカートのページなど、インデックス不要なページにはDisallowを設定することが推奨されます。ただし、robots.txtはあくまでも「お願い」であり、悪意のあるクローラーはこれを無視する可能性がある点には注意が必要です。
noindexタグの設定と活用方法
HTMLのmetaタグやHTTPヘッダーでnoindexが設定されていると、クローラーがページを発見してもインデックスに登録されません。WordPressなどのCMSを使用している場合、管理画面の設定で「検索エンジンがサイトをインデックスしないようにする」というオプションにチェックが入っていることがあります。この設定は、サイトの開発中や準備段階で有効にしていることが多く、公開時に解除し忘れるケースが頻繁に発生します。
URL検査ツールで「インデックス登録がブロックされました」というメッセージが表示された場合は、noindex設定を確認してください。一方で、管理画面やプライベートなコンテンツなど、意図的にインデックスから除外したいページにはnoindexを積極的に活用しましょう。HTMLのhead部分に所定のmetaタグを記述することで、そのページをインデックスしないようGoogleに指示できます。重要なページに誤ってnoindexを設定してしまうミスは非常に多いため、設定後は必ずURL検査ツールで確認することをおすすめします。
インデックスされない主な原因と対処法をまとめると、以下のようになります。
| 原因 | 症状 | 対処法 |
|---|---|---|
| robots.txtブロック | クローラーがアクセスできない | robots.txtのDisallow設定を確認・修正 |
| noindexタグ | クロールされるがインデックスされない | metaタグまたはHTTPヘッダーを確認・削除 |
| 低品質コンテンツ | インデックスから除外される | コンテンツの質と独自性を向上させる |
| 重複コンテンツ | 代表ページのみインデックスされる | canonicalタグで正規URLを指定 |
| サーバーエラー | 500エラーでクロール失敗 | サーバー環境の安定化と監視 |
コンテンツ品質と技術的な問題
Googleは低品質なコンテンツをインデックスから除外する傾向があります。他サイトからのコピーコンテンツ、自動生成された意味のないテキスト、ユーザーにとって価値のない薄い内容のページなどは、インデックスされにくくなっています。Googleのアルゴリズムは年々高度化しており、コンテンツの独自性や専門性、有用性を評価する精度が向上しています。単にキーワードを詰め込んだだけのページや、他サイトの内容を言い換えただけのページは、インデックスから除外される可能性が高くなっています。
また、重複コンテンツも問題となります。同じ内容のページが複数存在する場合、Googleはそのうちの1つだけを代表としてインデックスし、他は除外することがあります。これは、ECサイトで商品のカラーバリエーションごとにURLが分かれている場合や、パラメータ付きURLが大量に生成される場合などに起こりやすい問題です。canonicalタグを適切に設定して、正規ページを明示することが重要です。さらに、サーバーエラーや極端に遅いページ読み込み速度は、クローラーの正常な動作を妨げます。Google Search Consoleのクロール統計情報を確認し、エラーが発生していないかを定期的にチェックすることをおすすめします。

クローラビリティを向上させるための施策
クローラビリティとは、クローラーがサイト内を効率よく巡回できるようにすることを指します。クローラビリティが高いサイトは、新しいコンテンツが素早くインデックスされやすくなります。特に、数千〜数万ページ以上を持つ大規模サイトでは、クローラビリティの最適化がSEOにおいて重要な課題となります。クローラーがサイト内のすべてのページに効率的にアクセスできる状態を維持することで、新規コンテンツや更新コンテンツを素早くGoogleに認識してもらえます。
クローラビリティを考える上で重要な概念が「クロールバジェット」です。Googleはサイトごとに、一定期間内にクロールするページ数の上限を設けています。この上限を超えると、一部のページがクロールされないまま残ってしまいます。大規模サイトでは、不要なページへのクロールを制限し、重要なページに優先的にクロールバジェットを配分することが重要です。
XMLサイトマップの作成と送信
XMLサイトマップは、サイト内のページ一覧をクローラーに伝えるためのファイルです。このファイルをGoogle Search Consoleから送信することで、クローラーに効率的にサイト構造を伝えることができます。サイトマップには各ページのURL、最終更新日、更新頻度、優先度などの情報を含めることができます。これにより、クローラーは重要なページを優先的にクロールし、更新されたページを素早く認識できるようになります。
特に、サイト内のリンク構造が複雑な場合や、新しいページを頻繁に追加する場合には、XMLサイトマップの効果が顕著に現れます。リンクが少ない新規ページでも、サイトマップに含まれていればクローラーに発見してもらいやすくなります。WordPressであれば、Yoast SEOやAll in One SEO Packなどのプラグインを使用して自動的にサイトマップを生成できます。サイトマップは更新のたびに自動的に更新される設定にしておくことが望ましいです。
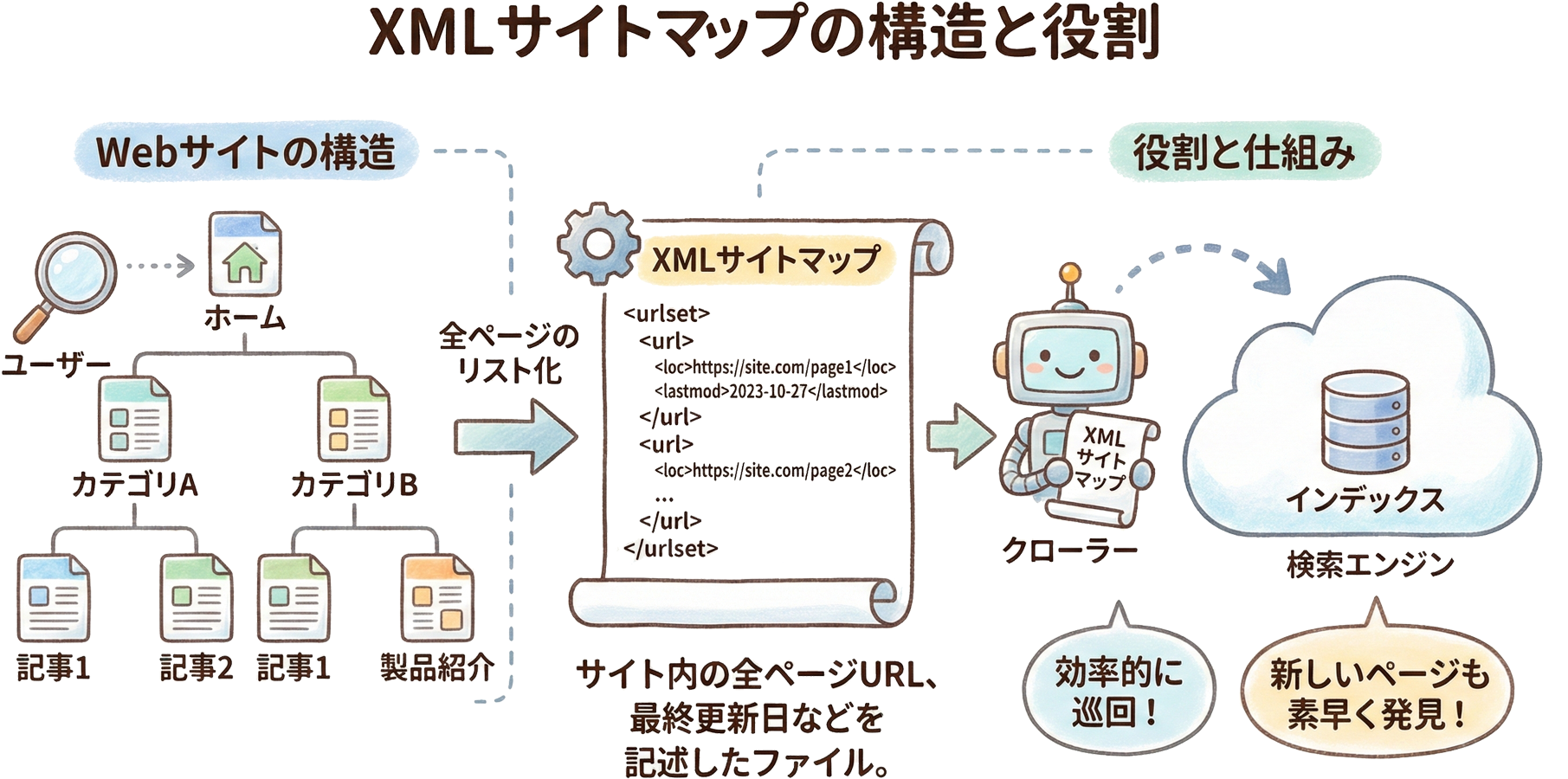
WordPressでXMLサイトマップを効率的に管理したい方には、投稿タイプ別にサイトマップを生成し、ニュース・画像・動画サイトマップにも対応する高機能プラグインがおすすめです。50,000件での自動分割やGZIP圧縮にも対応しており、大規模サイトでも効率的なクロールを実現できます。
内部リンク構造の最適化
クローラーはリンクをたどってサイト内を移動します。そのため、適切な内部リンク構造を構築することは、クローラビリティ向上の基本となります。重要なページにはトップページからできるだけ少ないクリック数でたどり着けるようにすることが理想的です。一般的に、トップページから3クリック以内で到達できるページは、クローラーに発見されやすく、重要なページとして認識されやすいとされています。
また、孤立したページを作らないことも重要です。どこからもリンクされていないページは、クローラーに発見されにくくなります。パンくずリストの設置、関連記事へのリンク、カテゴリーページの整備などを通じて、サイト全体が有機的につながった構造を目指しましょう。また、サイト内のリンク切れ(404エラー)はクローラビリティに悪影響を与えるため、定期的にリンク切れをチェックし、修正することも大切です。
クローラビリティを向上させるための主な施策は、以下の通りです。
- XMLサイトマップを作成してGoogle Search Consoleから送信する
- 内部リンクを適切に配置して孤立ページをなくす
- パンくずリストを設置してサイト階層を明確にする
- ページ読み込み速度を改善してクロールバジェットを有効活用する
- サーバーの安定性を確保してエラーを防止する
ページ速度とサーバー応答の改善
クローラーには「クロールバジェット」と呼ばれる、1回の訪問で巡回できるページ数の上限があります。ページの読み込みが遅いと、クローラーが巡回できるページ数が減少し、結果としてインデックスが遅れる原因となります。たとえば、1ページの読み込みに5秒かかるサイトと、0.5秒で読み込めるサイトでは、同じ時間内にクロールできるページ数に10倍の差が生じます。
画像の最適化、キャッシュの活用、不要なスクリプトの削除などを通じて、ページ速度を改善しましょう。Google PageSpeed InsightsやLighthouseなどのツールを使用して、ページ速度の問題点を特定し、改善することが推奨されます。また、サーバーの応答時間も重要な要素です。安定したホスティング環境を選択し、サーバーエラーが発生しないように監視することが大切です。サーバーが不安定でエラーが頻発すると、クローラーがページを正常に取得できず、インデックスに悪影響を与えます。
よくある質問
まとめ
クローラーとインデックスは、検索エンジンがWebサイトを認識し、検索結果に表示するための基盤となる仕組みです。クローラーはWebページを発見し情報を収集するプログラムであり、インデックスはその情報をデータベースに登録する処理です。この2つのプロセスを理解することで、なぜ自分のページが検索結果に表示されないのか、どうすれば改善できるのかを論理的に考えられるようになります。
Google Search Consoleを活用してインデックス状況を定期的に確認し、問題があれば原因を特定して対処していくことが、SEO成功への近道です。インデックス登録をリクエストした後、実際に反映されるまでの時間は状況によって異なりますが、焦らず待ちつつコンテンツの品質や技術的な問題がないかを見直すことが大切です。
また、現在Googleはモバイル版のページを優先的にクロール・インデックスする「モバイルファーストインデックス」を採用しています。レスポンシブデザインを採用している場合は特に問題ありませんが、モバイル対応状況は定期的にチェックしましょう。技術的な問題、コンテンツ品質、サイト構造など、さまざまな要因が絡み合っていますが、一つひとつ着実に改善していくことで、検索エンジンからの評価を高めていくことができます。
SEO Note! Team (SEO施策スタッフ)
SEOエンジニア、マーケター、ライター、編集担当からなる専門チームです。技術的なサイト最適化からコンテンツ戦略の立案、記事の執筆・編集まで、SEO施策を一気通貫で対応できる体制を整えています。10万パターン以上のキーワード対策と3万を超えるドメインの運用で培った実践的なノウハウをもとに、机上の理論だけでは得られない現場視点のSEO支援を提供しています。
関連記事




